Key Takeaways from Claude Opus 4.6
- Claude Opus 4.6 introduces Causal Chain Synthesis (CCS) for deeply enhanced, multi-step logical reasoning across diverse data formats.
- The model offers significant performance improvements, including up to 60% faster benchmark speeds and noticeably quicker real-world response times.
- Anthropic's new pricing strategy for Opus 4.6 incentivizes concise input and rewards detailed output, potentially optimizing costs for specific use cases.
- Migration is straightforward, mainly requiring a model identifier update, though developers should re-evaluate prompts for new efficiencies.
- Beyond official updates, Opus 4.6 demonstrates improved multilingual code understanding, implicit state tracking, and more reliable structured data output.
- The release reinforces Anthropic's commitment to safety with Constitutional AI v3.0, featuring nuanced ethical disambiguation and proactive bias detection.
Claude Opus 4.6: A Deep Dive into Anthropic's Latest Flagship AI
Anthropic has officially rolled out Claude Opus 4.6, its newest large language model, bringing significant advancements to the AI landscape.
This iteration introduces a sophisticated reasoning paradigm and substantial performance upgrades that aim to redefine how developers and enterprises interact with AI.
Released on February 9, 2026, Opus 4.6 is designed to tackle complex challenges with improved logical capabilities, enhanced efficiency, and a revised pricing structure.
This guide offers a practical analysis of its core features, real-world implications, and what to consider for effective integration.
Opus 4.6's Enhanced Reasoning: A Practical Analysis
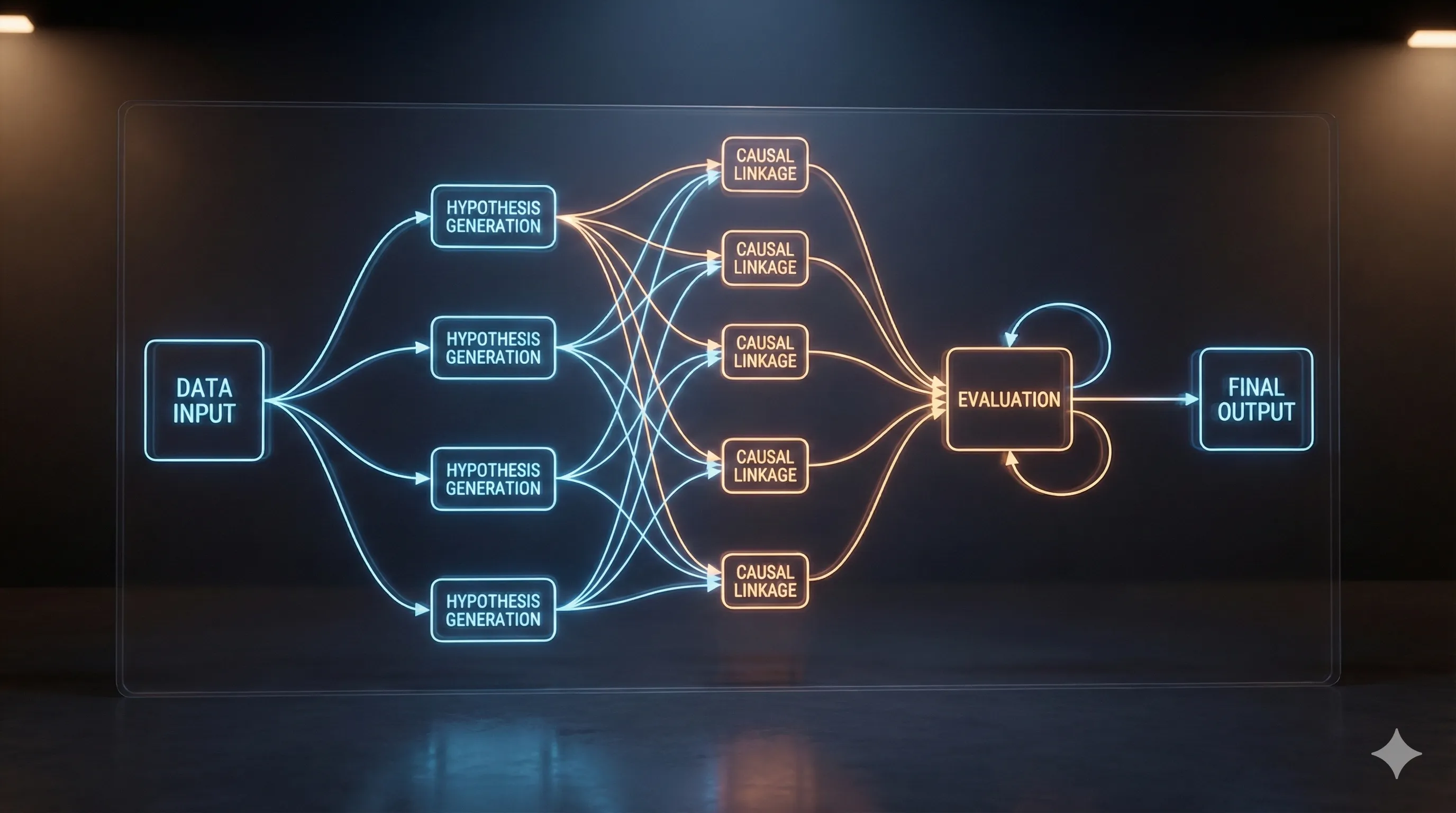
At the core of Claude Opus 4.6 is a new proprietary reasoning architecture known as "Causal Chain Synthesis" (CCS).
Unlike earlier models that primarily focused on pattern matching, CCS constructs and evaluates logical causal chains before generating an answer.
This fundamental shift leads to a noticeable improvement in tasks that demand deep, multi-step logic.
How CCS Translates to Real-World Performance:
- Complex Problem-Solving:
Opus 4.6 can cross-reference information from various data formats, such as CSVs, PDFs, and TXT files, to identify conflicting data and propose hypotheses based on logical deductions.
This is particularly useful for intricate business analyses. - Advanced Scientific Reasoning:
The model can analyze methodologies in academic papers, pinpoint potential flaws in experimental designs, or suggest alternative hypotheses that might have been overlooked. - Coding & System Diagnostics:
For developers, Opus 4.6 can analyze a complex stack trace from a microservices architecture, reason about potential failure points across different services, and suggest targeted debugging steps.
It moves beyond simple syntax fixes to provide architectural-level insights.
Consider a common development scenario:
A developer needs to diagnose a `CrashLoopBackOff` error in an `auth-service` pod within a 500-line Kubernetes configuration.
- Opus 4.5 (Previous Gen):
Might identify a basic syntax error or a missing environment variable within the `auth-service` definition. - Opus 4.6 (with CCS):
Can trace service dependencies, notice that the `auth-service` relies on a database with a misconfigured readiness probe, and conclude that the authentication service is crashing because its essential dependency is unavailable.
This identifies a full causal chain of failure.
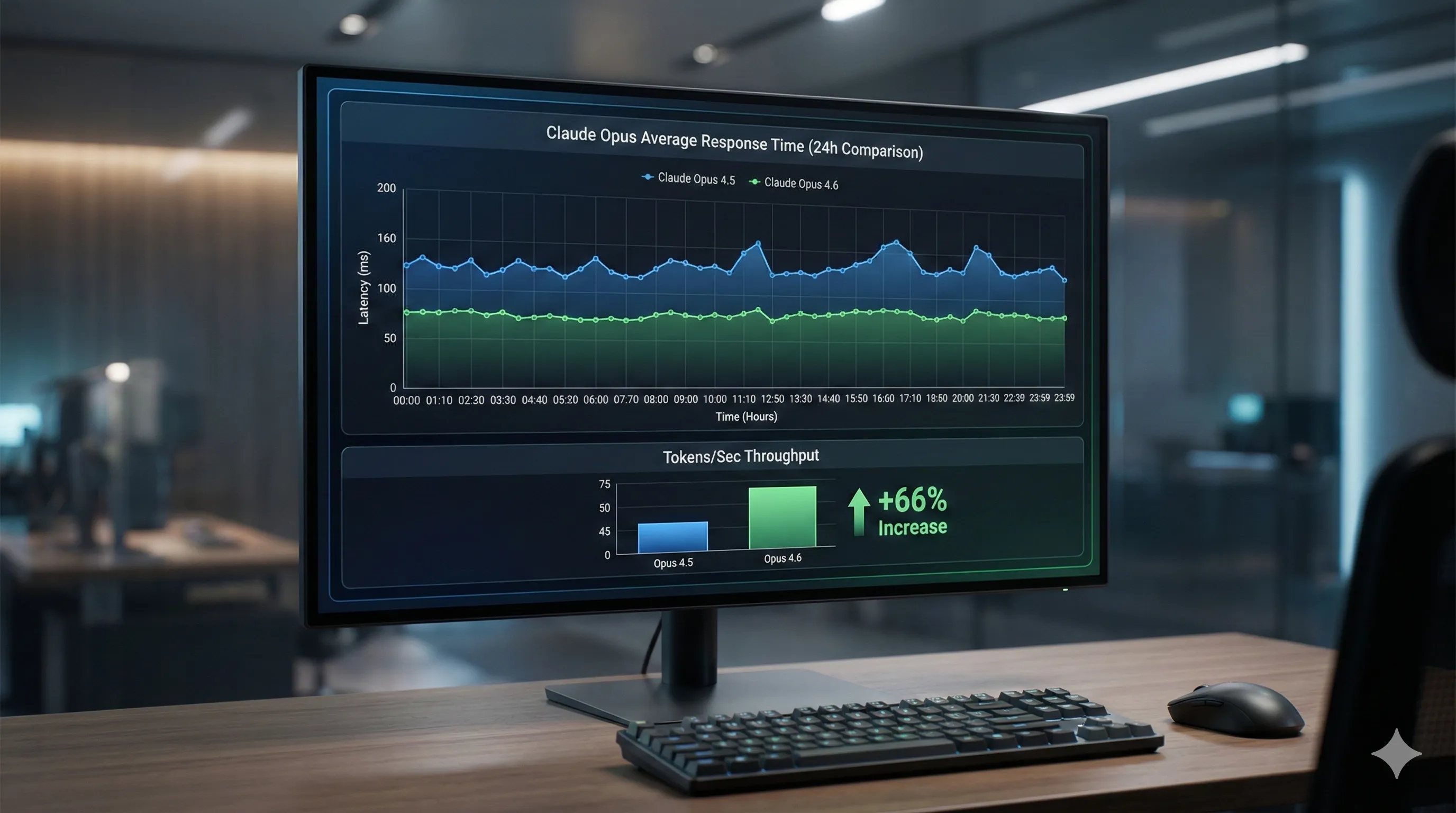
Claude Opus 4.6: Benchmarks vs. Real-World Speed & Efficiency
Anthropic states that Opus 4.6 is up to 60% faster than its predecessor (Opus 4.5) on complex instruction-following benchmark tests.
This claim translates into tangible benefits for users in everyday applications.
| Metric | Claude Opus 4.5 (Legacy) | Claude Opus 4.6 (New) | Analysis |
|---|---|---|---|
| MMLU Score | 90.1% | 93.4% | A significant gain in general knowledge and problem-solving capabilities. |
| HumanEval (Coding) | 93.2% | 96.5% | The model is nearing human-level performance on standard coding challenges. |
| Avg. Tokens/Sec (Chat) | ~45 tokens/sec | ~70 tokens/sec | Noticeably faster and more fluid for interactive use cases. |
| Throughput (Batch API) | ~180 tokens/sec | ~250 tokens/sec | A major improvement for enterprise-scale data processing jobs and high-volume tasks. |
Real-World Impact:
- Response Times:
For chat applications, the perceived latency is much lower, making conversations feel more natural and less disjointed. - Computational Costs:
Despite its increased power, the architectural efficiencies of Opus 4.6 can lead to shorter job times for certain batch processing tasks.
This efficiency could result in lower overall compute costs, even with potential per-token price adjustments. - Energy Usage:
Anthropic emphasizes that the model's efficiency gains contribute to a lower energy cost per query.
This aligns with responsible AI scaling and is a vital consideration for large-scale enterprise deployments.
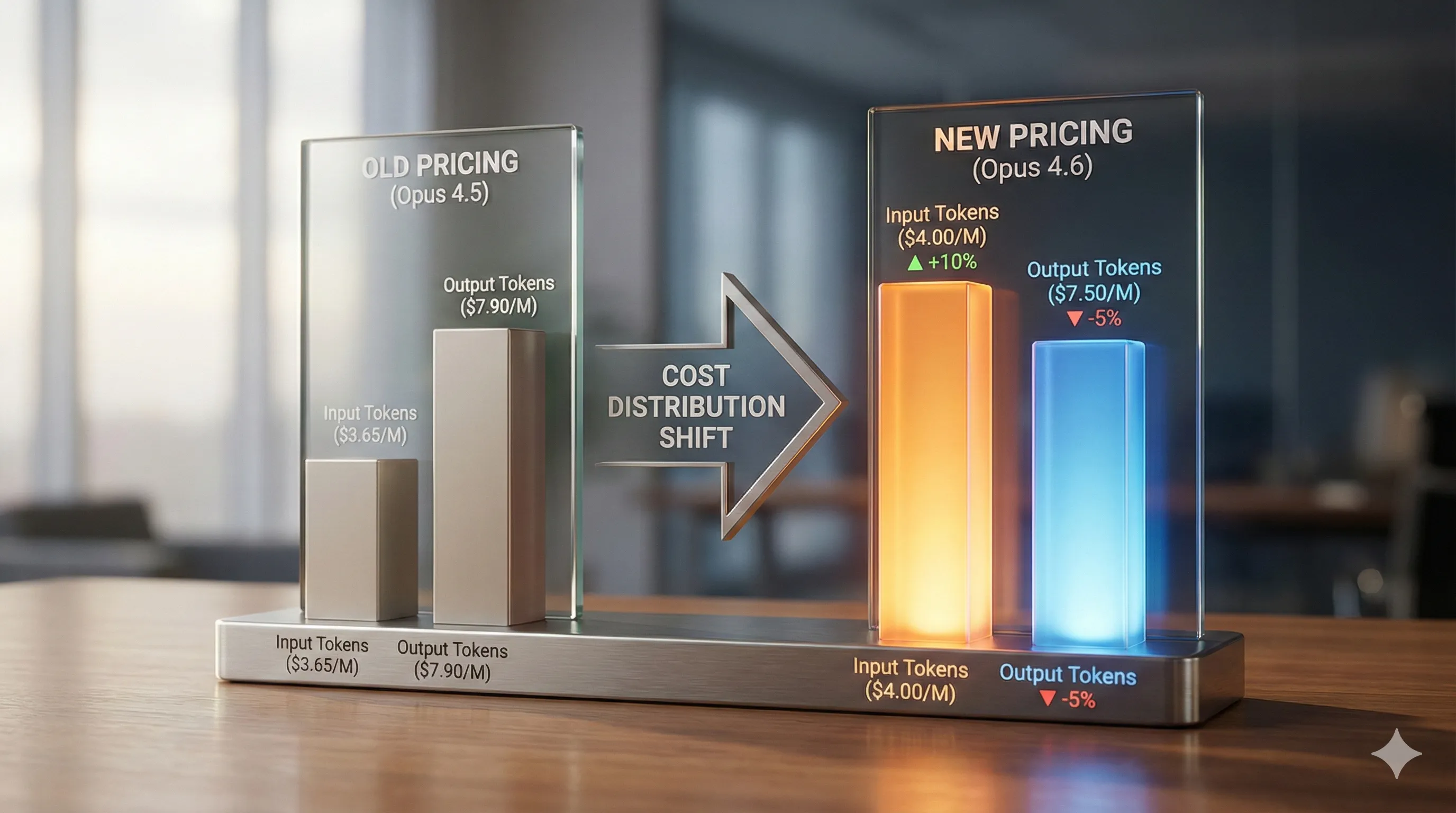
Is Claude Opus 4.6 Worth the New Pricing Model?
Opus 4.6 introduces a refined pricing structure that has garnered significant attention.
It moves beyond a simple flat rate, seemingly designed to encourage more efficient prompt engineering.
Illustrative New Pricing (API):
- Input Tokens: $4.00 per million tokens (a 10% increase compared to 4.5).
- Output Tokens: $7.50 per million tokens (a 5% decrease compared to 4.5).
Cost-Benefit Analysis:
- For Developers:
This model encourages developers to craft concise and effective prompts.
Applications that feed large amounts of context but require short, precise answers (e.g., classification, data extraction) might see a net cost increase.
Conversely, applications generating long, detailed outputs from brief instructions (e.g., code generation, extensive report writing) could become more cost-effective to run. - For Enterprises:
The enhanced performance, improved reasoning, and robust safety features are likely to justify the adjusted cost.
The ability to solve more complex problems with higher accuracy often yields a significant return on investment that outweighs minor pricing shifts. - Individual Power Users (Pro Subscription):
The Claude Pro subscription is projected to increase from $20/month to $25/month to reflect the new capabilities.
For users who rely on Claude for professional coding, detailed writing, or in-depth analysis, the performance gains will likely make this a worthwhile investment.
Migrating to Opus 4.6: API Changes & Workflow Adjustments
Anthropic has prioritized a smooth migration path for developers adopting Opus 4.6.
Fortunately, there are no major breaking changes in the core API structure.
Key Changes:
- Model Name Update:
The primary change involves updating the model identifier in your API calls.
Replace `claude-opus-4.5` (or similar) withclaude-opus-4.6-20260209. - New Optional Parameter:
A new parameter,reasoning_mode, can be set to"ccs_enabled": trueto explicitly utilize the new Causal Chain Synthesis engine.
While CCS is the default, manually setting this parameter ensures you are leveraging the new feature. - Tool Use & Function Calling:
The schema for tool use has been refined for improved robustness, offering better error handling for malformed JSON.
Developers should consult the updated documentation to optimize their function-calling implementations.
Best Practices for Migration:
- Staged Rollout:
Always test Opus 4.6 in a staging environment first.
The model's improved reasoning might produce slightly different (and likely superior) outputs, which could impact downstream processes. - Prompt Evaluation:
Review and re-evaluate your existing core prompts.
Prompts that were heavily engineered to overcome limitations in previous models may now be simplified to achieve better performance and potentially lower costs. - Monitor Costs:
Implement a dashboard to closely track your token usage during the initial migration period.
This helps in understanding the real-world impact of the new pricing model on your specific applications.
For comprehensive details, developers should refer to the official Anthropic developer documentation.

Early Adopter Feedback: Common Bugs & Community Concerns with Opus 4.6
Within the first week of its release, discussions across developer forums and social media have highlighted several emerging themes regarding Claude Opus 4.6.
- Initial Latency Spikes:
Some users observed inconsistent "cold start" latency during the first 48 hours.
This appears to be stabilizing as Anthropic's infrastructure scales to meet demand. - Overly Cautious Refusals:
The updated safety and reasoning systems can occasionally be *too* cautious.
The model has been noted to refuse borderline-ambiguous prompts that older versions might have handled, particularly in complex creative writing scenarios. - Cost Management Concerns:
Developers are actively debating the new input/output pricing split.
Some express worry about the potential cost implications for context-heavy Retrieval-Augmented Generation (RAG) applications. - Minor Hallucinations in Code:
While coding abilities are significantly improved, there have been rare, unverified community reports of the model hallucinating non-existent library functions when dealing with highly niche or newly released programming frameworks.

Undocumented Features & Hidden Gems in Claude Opus 4.6
Beyond the official changelog, the developer community has started to uncover subtle yet powerful enhancements within Claude Opus 4.6.
- Enhanced Multilingual Code Understanding:
Opus 4.6 demonstrates a surprisingly robust capability to understand and maintain code where comments and variable names are in a different language than the programming language itself.
For example, it can correctly infer logic from Python code with Japanese comments without confusion. - Implicit State Tracking in Long Conversations:
The model appears to have a significantly improved capacity for tracking implicit tasks and user intent over extended conversations.
This leads to more coherent, multi-turn interactions, reducing the need for constant re-prompting and making dialogues flow more naturally. - More Reliable Structured Data Output:
When tasked with generating structured formats like JSON or XML, Opus 4.6 is notably more resilient to prompt-based attempts to break its structure.
It consistently delivers well-formed output, improving reliability for integration with other systems.

Claude Opus 4.6 vs. The Competition: A Head-to-Head Battle
As of February 2026, Claude Opus 4.6 faces direct competition from OpenAI's GPT-5 and Google's Gemini Ultra 1.5.
Here’s a high-level comparison based on initial testing and stated capabilities.
| Feature/Capability | Claude Opus 4.6 | GPT-5 (Rumored/Early Info) | Gemini Ultra 1.5 |
|---|---|---|---|
| Core Strength | Causal Reasoning & Enterprise Safety | Raw Creativity & General Knowledge | Native Multimodality & Google Ecosystem Integration |
| Coding | Excellent, especially for debugging & architecture analysis | Excellent, especially for novel algorithm generation | Strong, especially for Android/web development within the Google ecosystem |
| Safety & Alignment | Industry-leading; Constitutional AI v3.0 | Strong, but with more flexibility and potentially fewer guardrails | Strong, with deep integration into Google's extensive safety tools |
| API Customization | Moderate; focused on reliability and controlled environments | High; extensive fine-tuning options and flexibility | High; extensive Vertex AI integration for custom model deployment |
| Pricing | Premium, value-focused on complex problem-solving | Expected to be highly competitive and tiered for various uses | Integrated with Google Cloud credits and pricing structures |
Claude Opus 4.6 is carving out its niche as the preferred choice for enterprises and developers who prioritize safety, reliability, and sophisticated reasoning for complex, mission-critical tasks.

Opus 4.6's Evolving Safety & Ethical AI Considerations
Anthropic continues to build upon its strong foundation of Constitutional AI (CAI) with the introduction of CAI v3.0 in this release.
This update brings several advancements focused on ethical AI and responsible deployment.
- Nuanced Ethical Disambiguation:
The model is better equipped to handle complex ethical dilemmas that lack clear-cut answers.
Instead of simply refusing a prompt, it now tends to analyze the underlying ethical frameworks (e.g., utilitarianism, deontology) and discusses the problem's nuances, guiding the user toward a safer conclusion. - Proactive Bias Detection:
Opus 4.6 incorporates a mechanism to self-critique its potential outputs for hidden biases before finalizing generation.
This feature significantly reduces the likelihood of producing subtly stereotyped or prejudiced content. - Misuse Prevention:
The model has undergone specific fine-tuning to enhance its ability to detect and refuse prompts related to emerging threats.
This includes sophisticated disinformation campaigns or the generation of malicious code for novel cyberattacks, bolstering its role as a safer AI.

Leveraging Opus 4.6 for Advanced Code Generation & Debugging
Developers can harness the new capabilities of Claude Opus 4.6 to move beyond basic boilerplate code generation and into more sophisticated problem-solving.
Best Practices:
- Use it as an Architectural Sounding Board:
Before you even start writing code, describe your system's architecture and goals to Opus 4.6.
Ask it to identify potential bottlenecks, security vulnerabilities, or scalability issues in your design.
Its Causal Chain Synthesis allows it to reason about how different components will interact. - Leverage "Pre-compilation Logic Analysis":
Paste a complex function into the chat and prompt it with: "Analyze this code for logic errors, race conditions, and edge cases that unit tests might miss."
Opus 4.6 can often pinpoint flaws in business logic that are syntactically correct but functionally flawed. - Complex Debugging:
When debugging, provide more than just an error message.
Include the error, the relevant code snippet, and a concise description of the intended behavior.
This comprehensive context allows the model to fully utilize its reasoning power to find the root cause, which is frequently located outside the code that is actively throwing the error.
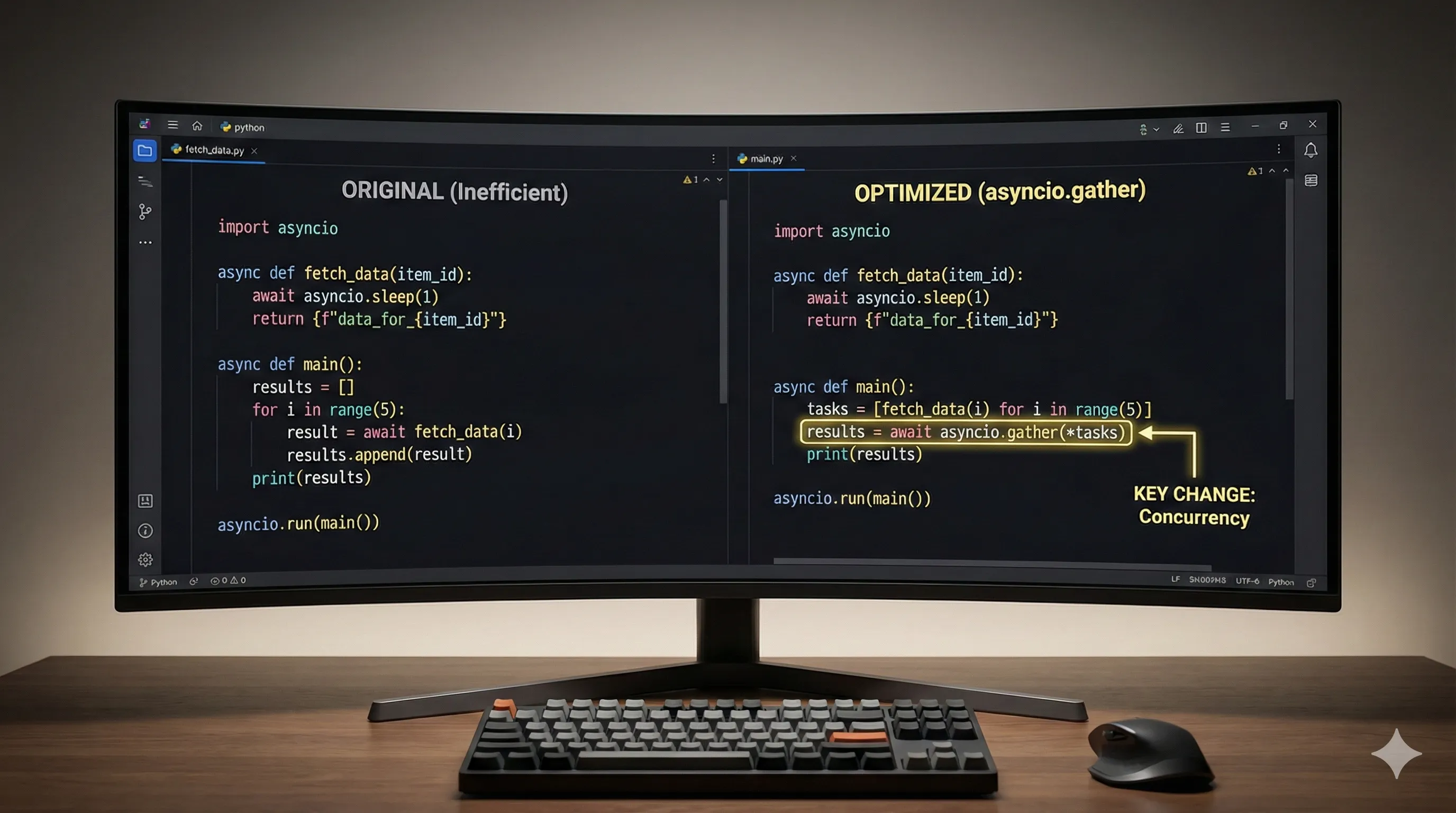
Here's an example of Opus 4.6 optimizing inefficient `asyncio` code:
# User provides this code:
import asyncio
async def fetch_data(item_id):
# Simulates a network call
await asyncio.sleep(1)
return {f"data_for_{item_id}"}
async def main():
results = []
for i in range(5):
# This is an anti-pattern!
result = await fetch_data(i)
results.append(result)
print(results)
asyncio.run(main())
# User prompt: "This Python asyncio code is slow. How can I optimize it?"
# Opus 4.6 Response:
"The provided code is inefficient because it's running asynchronous operations serially.
You are using `await` inside a `for` loop, which defeats the purpose of asyncio.
To run these tasks concurrently and achieve a significant speedup, you should use `asyncio.gather`.
Here is the optimized version:
python
import asyncio
async def fetch_data(item_id):
# Simulates a network call
await asyncio.sleep(1)
return {f"data_for_{item_id}"}
async def main():
tasks = [fetch_data(i) for i in range(5)]
results = await asyncio.gather(*tasks)
print(results)
asyncio.run(main())
This revised code will execute all five `fetch_data` calls concurrently, reducing the total execution time from approximately 5 seconds to 1 second."