🚀 Key Takeaways
- The release of GPT-5.4 mini and GPT-5.4 nano on March 17, 2026, introduces significantly faster, more cost-effective, and highly capable small models from the GPT-5.4 family.
- GPT-5.4 mini offers near-GPT-5.4 performance for its size, running over 2x faster than GPT-5 mini and optimized for executing complex subtasks like scanning codebases and drafting PRs while using only 30% of the GPT-5.4 quota.
- GPT-5.4 nano is positioned as the cheapest GPT-5.4-class model for high-volume simple tasks, delivering strong competitive benchmarks against rivals like Claude Haiku 4.5 and offering remarkable pricing, particularly for cached inputs.
The world of artificial intelligence is set to expand its horizons with the upcoming release of GPT-5.4 mini and GPT-5.4 nano on March 17, 2026.
These groundbreaking models represent a pivotal step in making advanced AI more accessible and efficient, distilling the immense power of the full GPT-5.4 into smaller, faster, and more specialized packages.
Designed to excel in a variety of demanding scenarios, both mini and nano are meticulously optimized for coding, tool use, and multimodal reasoning. GPT-5.4 mini stands out as a rapid executor for complex subtasks within larger AI workflows, delivering performance surprisingly close to the full GPT-5.4 while running more than 2x faster than its predecessor, GPT-5 mini. Meanwhile, GPT-5.4 nano emerges as the most cost-effective solution for simple, high-volume tasks, boasting strong competitive benchmarks against rivals like Claude Haiku 4.5 and offering incredibly low pricing, especially for cached inputs.
These new additions promise to unlock unprecedented levels of efficiency and affordability, enabling developers and businesses to integrate cutting-edge AI capabilities into applications that demand speed, scalability, and cost-consciousness. The introduction of GPT-5.4 mini and nano marks a significant evolution, ensuring that top-tier AI performance is not only powerful but also practically deployable across a wider spectrum of use cases.

1. Mark Your Calendars: The Grand Arrival of GPT-5.4 Mini & Nano
🔹 The Unified Launch Day
The wait is officially ending, with a coordinated release that promises immediate, broad-spectrum access.
Both GPT-5.4 mini and GPT-5.4 nano are confirmed for a simultaneous global launch on March 17, 2026.
From day one, these models will be available across the entire developer and consumer ecosystem through the API, integrated directly into Codex, and accessible within the main ChatGPT interface.
🔹 Your Workflow, Your Access Point
This three-pronged release strategy ensures that no matter how you use AI, the new models are ready for you.
For developers and businesses, immediate API access means you can start building with the new mini and nano models in your own applications on launch day, without any delay.
Coders will find their workflows instantly upgraded, as the models will be natively available within Codex to assist with everything from boilerplate code to complex debugging.
And for the millions of daily users, the seamless integration into ChatGPT means you'll be able to leverage the power of these new models for your questions, drafts, and creative tasks right from your familiar chat window.
🔹 An Ecosystem-Wide Upgrade
This isn't a staggered rollout; it's a strategic, full-scale deployment designed for maximum impact.
Launching on all platforms at once shows a powerful commitment to making these new tools ubiquitous from the get-go.
The community's anticipation is centered on this immediate availability, which allows everyone from enterprise API users to casual chatbot enthusiasts to start experimenting and innovating simultaneously.
Get ready for March 17, 2026—it's less of a product release and more of a foundational upgrade for the entire AI landscape.

2. Your Gateway to AI Power: Navigating GPT-5.4 Mini & Nano Access Points
🔹 The Trifecta of Access: Where to Find Mini & Nano
Getting your hands on the new GPT-5.4 mini and nano models is refreshingly straightforward.
Both of these compact powerhouses are available through the exact same three core interfaces.
Users can interact with them via the raw power of the `API`, the developer-focused `Codex`, and the widely accessible `ChatGPT` platform.
This unified availability ensures that no matter your technical skill level, there's a direct path to leveraging their capabilities.
🔹 From Custom Apps to Casual Chats: Picking Your Playground
This three-pronged strategy brilliantly caters to distinct user needs.
For businesses and developers, the `API` is the ultimate sandbox, allowing you to embed mini or nano's intelligence directly into your own applications, from a lightning-fast customer support bot to an internal data analysis tool.
Coders will feel right at home in `Codex`, using it as a supercharged pair-programmer to draft functions, debug complex logic, and accelerate development cycles with model-assisted precision.
Meanwhile, the `ChatGPT` interface serves as the universal front door, offering a simple, conversational way for marketers, students, and writers to tap into the models' power for brainstorming, summarizing text, or generating creative content without writing a single line of code.
🔹 Expert's Verdict: A Unified Yet Segmented Ecosystem
The decision to deploy both mini and nano across all three access points is a masterstroke in user experience.
It eliminates fragmentation and ensures that the core technology is available to the widest possible audience, from enterprise developers to casual hobbyists.
My pro-tip is to match the tool to the task: live in the `API` for custom builds, make `Codex` your go-to for development, and leverage the speed and simplicity of `ChatGPT` for daily productivity boosts.
This isn't about choosing the best interface; it's about choosing the right interface for what you need to accomplish at that moment.

3. GPT-5.4 Mini: The Compact Powerhouse for Diverse Applications
🔹 Near-Flagship Power in a Nimble Package
Positioned as the most capable small model yet, GPT-5.4 mini is engineered as a smaller, significantly faster version of the full GPT-5.4 model.
It's specifically optimized for high-demand tasks including Coding, Tool use, Multimodal reasoning, and serving High-volume API requests.
Performance benchmarks are stunning for a model of its size, delivering results that are surprisingly close to the full GPT-5.4 model while running much faster.
Compared to its predecessor, it represents a monumental leap, significantly improving over GPT-5 mini across all key metrics and running more than 2x faster.
Testing shows it consistently outperforms the older GPT-5 mini at similar latencies and even approaches GPT-5.4-level pass rates on specific tasks, proving it doesn't compromise heavily on quality for speed.
🔹 The AI System's Hyper-Efficient Task Runner
This isn't just about a faster model; it's about a smarter workflow.
Imagine a developer using a multi-model system where the full GPT-5.4 handles the high-level planning and architectural judgment for a new software feature.
Instead of getting bogged down, the main model delegates the grunt work—like rapidly scanning entire codebases for dependencies or drafting initial pull requests—to GPT-5.4 mini, which executes these subtasks in a fraction of the time.
Similarly, a data analyst could task the system with understanding customer feedback from a product survey.
The flagship model devises the analysis strategy, while the Mini model is unleashed to perform the high-volume multimodal task of interpreting hundreds of user-submitted screenshots to identify common UI frustrations, acting as a tireless and swift assistant.
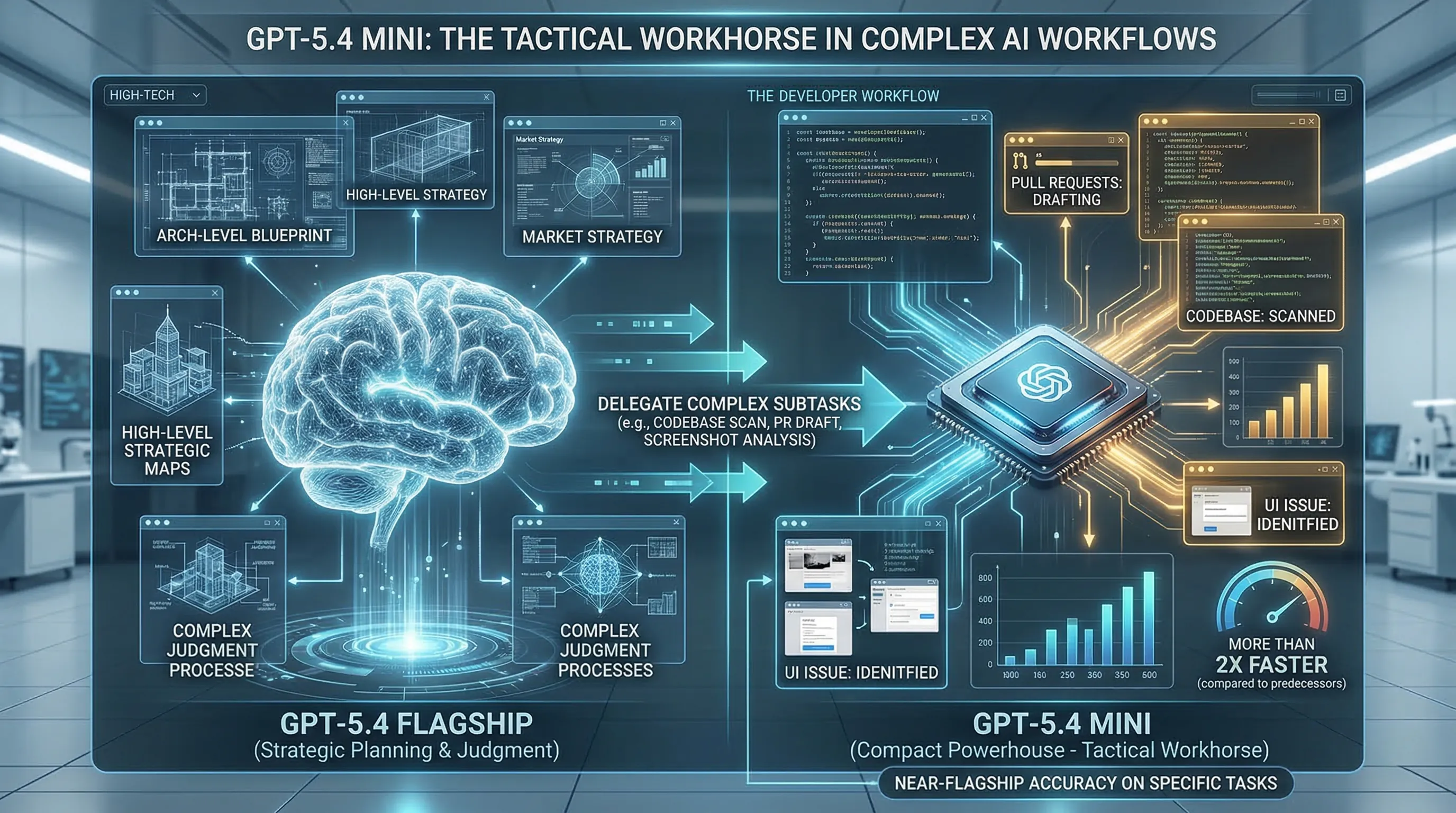
🔹 The Verdict: The Unsung Hero of Complex AI Workflows
While the flagship GPT-5.4 rightfully earns praise for its strategic planning capabilities, GPT-5.4 mini is the tactical workhorse that makes complex, multi-step operations viable and cost-effective.
It embodies the perfect balance of speed and competence, designed not to replace the main model, but to augment it.
Its true genius lies in its role as a specialized executor within a larger system.
By handling discrete, high-frequency subtasks with near-flagship accuracy, it frees up the more powerful model to focus on what it does best: judgment and complex problem-solving.
This symbiotic relationship is the future of building sophisticated, responsive, and efficient AI-powered applications.
4. GPT-5.4 Nano: The Ultra-Efficient Engine for High-Volume and Cost-Effective Tasks
🔹 Pocket Rocket Power at Pennies Per Prompt
Described as the most capable small model yet, GPT-5.4 nano is engineered from the ground up to be the cheapest GPT-5.4-class model for simple, high-volume tasks.
Its core optimizations target critical, high-throughput areas: Coding, Tool use, Multimodal reasoning, and especially the High-volume API.
The pricing structure is its most disruptive feature, coming in at an astonishingly low $0.20 per 1 million input tokens and a mere $1.25 per 1 million output tokens.
Even more impressive is the cached input pricing of just $0.02 per million tokens, making repeated queries on the same context almost free.
In head-to-head competition, it establishes clear dominance over rivals like Claude Haiku 4.5, scoring 9.8% higher on the challenging GPQA Diamond benchmark and also achieving higher scores on the specialized τ2-bench Telecom benchmark.
🔹 The New Workhorse for Your AI-Powered Business
This isn't just about saving a few dollars; the nano model unlocks entire business models previously deemed too expensive to operate at scale.
Imagine an e-commerce platform using its multimodal reasoning to instantly scan and categorize tens of thousands of new product images daily for a fraction of a cent per image.
A SaaS company can now offer an AI-powered customer support chatbot to every user on its free tier, handling millions of routine queries with the intelligence of a premium model but at a cost that doesn't tank the balance sheet.
For developers, this means running continuous integration checks, code linting, and documentation generation across massive repositories without ever worrying about API costs spiraling out of control.
The superior benchmark scores against competitors like Claude Haiku 4.5 provide crucial peace of mind; you're not sacrificing critical reasoning capability for cost savings, making it a safe and powerful choice for specialized industry tasks like analyzing telecom network data.
🔹 Redefining the "Good Enough" AI Standard
The community's take is clear: GPT-5.4 nano is the new baseline for any application that requires speed, scale, and cost-efficiency without a catastrophic drop in intelligence.
It's the perfect engine for powering fleets of autonomous agents that perform repetitive digital chores, from data scraping to filling out forms, where speed and volume are paramount.
Expert developers are already architecting systems where nano handles the initial, high-volume data triage or content generation, escalating only the most complex edge cases to the more expensive, full GPT-5.4 model.
This model effectively commoditizes GPT-5.4-class intelligence for the masses, moving it from a premium resource to an everyday utility.
While it won't write your novel or architect a revolutionary new system, it will flawlessly execute the million small tasks that enable those larger ambitions, making it perhaps the most impactful release for real-world product integration.

5. Beyond Basics: Advanced Strategies for GPT-5.4 Mini & Nano Power Users
🔹 The Specialist's Toolkit: Optimized & Redundant by Design
The true power of these new models lies in their specific, targeted optimizations.
Both GPT-5.4 mini and GPT-5.4 nano are purpose-built for high performance in four key domains: Coding, Tool use, Multimodal reasoning, and High-volume API calls.
Beyond this shared focus, GPT-5.4 mini introduces a groundbreaking architectural role within the ecosystem.
It serves as an automatic rate limit fallback for the full GPT-5.4 Thinking model, ensuring continuous operation for all users during peak loads.
More strategically, it's designed as a high-speed execution engine within a multi-model system, perfectly suited to rapidly handle subtasks like scanning codebases, drafting PRs, and interpreting screenshots when the main GPT-5.4 model is orchestrating the high-level planning and judgment.
🔹 Building a Resilient, High-Throughput AI Workforce
This isn't just about having smaller models; it's about architecting a smarter, more resilient AI system.
Imagine your primary application hits its GPT-5.4 usage limit during a critical product demo; instead of failing, the system seamlessly defaults to GPT-5.4 mini, maintaining functionality without any manual intervention.
This creates a level of operational reliability that was previously impossible, turning potential outages into non-events.
For developers building complex agents, the real magic is in the new division of labor.
You can now have GPT-5.4 act as a project lead, taking a vague command like "Analyze our latest user feedback and draft a response" and breaking it down.
It then dispatches a fleet of Mini agents: one to interpret screenshots of user issues, another to scan codebases for relevant functions, and a third to use tools to fetch user data, all in parallel.
This multi-agent approach, leveraging Mini as the fast and focused "doer," is how you go from minutes to seconds on complex, multi-step tasks.
Meanwhile, the high-volume API optimization on both models, especially Nano, unlocks entirely new product categories for mass-market data processing at scale.
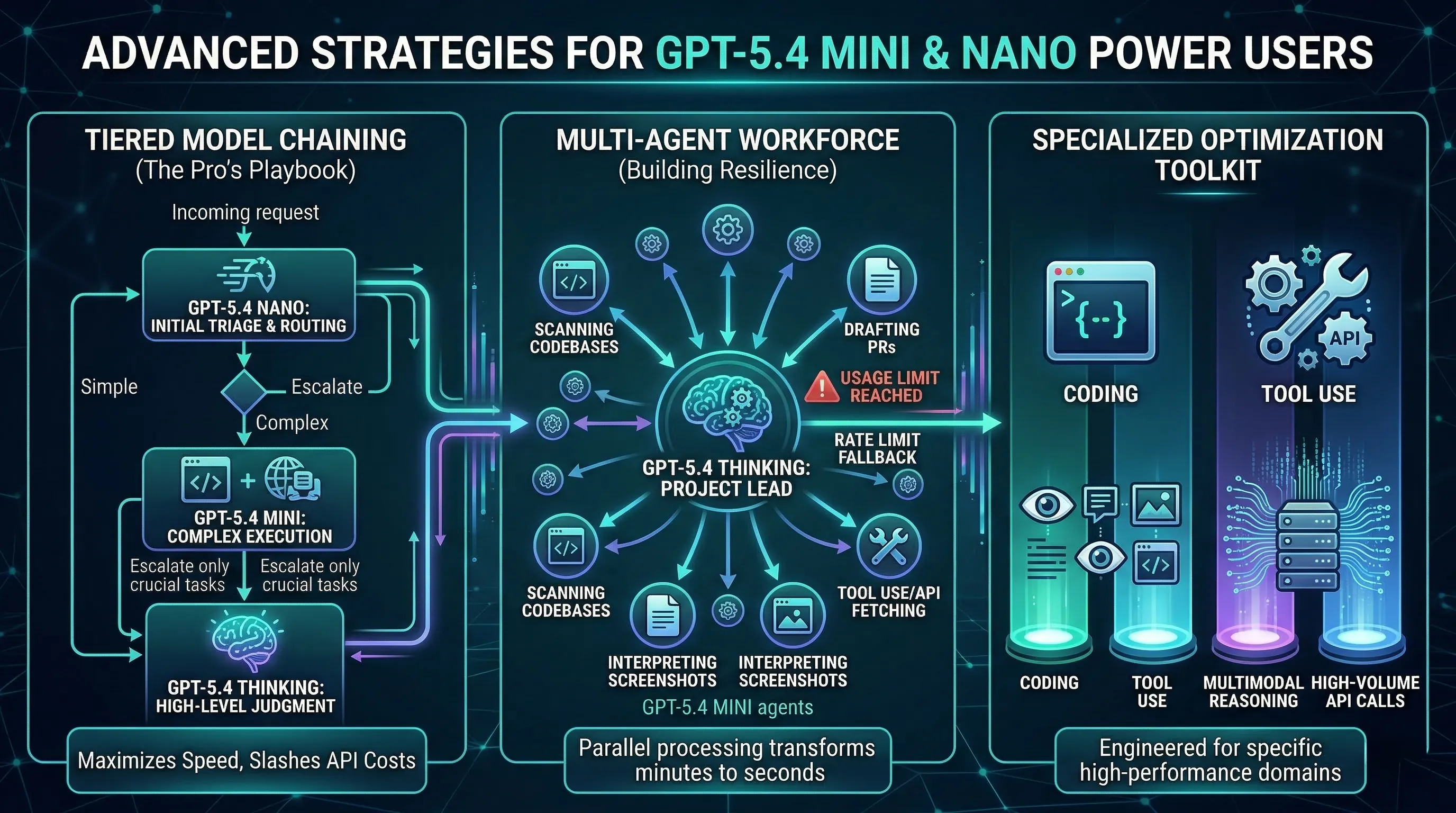
🔹 The Pro's Playbook: Chaining Models and Exploiting Redundancy
The most advanced teams are already treating this not as a choice between models, but as a tiered system to be exploited.
The expert strategy is to create "model chains": use the incredibly cheap GPT-5.4 Nano to handle initial, high-volume tasks like routing user intents or cleaning data.
Only if a task is identified as complex is it escalated to GPT-5.4 mini for its powerful coding or multimodal reasoning capabilities.
This tiered approach dramatically slashes API costs while maximizing speed for the majority of user interactions.
Furthermore, power users are starting to treat the rate limit fallback not as a safety net, but as a strategic feature.
You can intentionally design your applications to push certain non-critical, high-frequency background tasks to the point of rate-limiting the main model, knowing the highly-capable Mini will reliably take over.
This allows you to preserve your primary GPT-5.4 quota for the absolutely mission-critical moments that require its unique judgment.
Ultimately, the paradigm shift is to stop seeing Mini and Nano as "lesser" and start seeing them as hyper-efficient specialists for the exact jobs they were built to do.
6. Smart Spending, Smart AI: Optimizing Costs and Workflows with Mini & Nano
🔹 The Price Tag Decoded: A Tale of Two Tiers
The true power of these new models is revealed in their aggressive and strategic pricing structures.
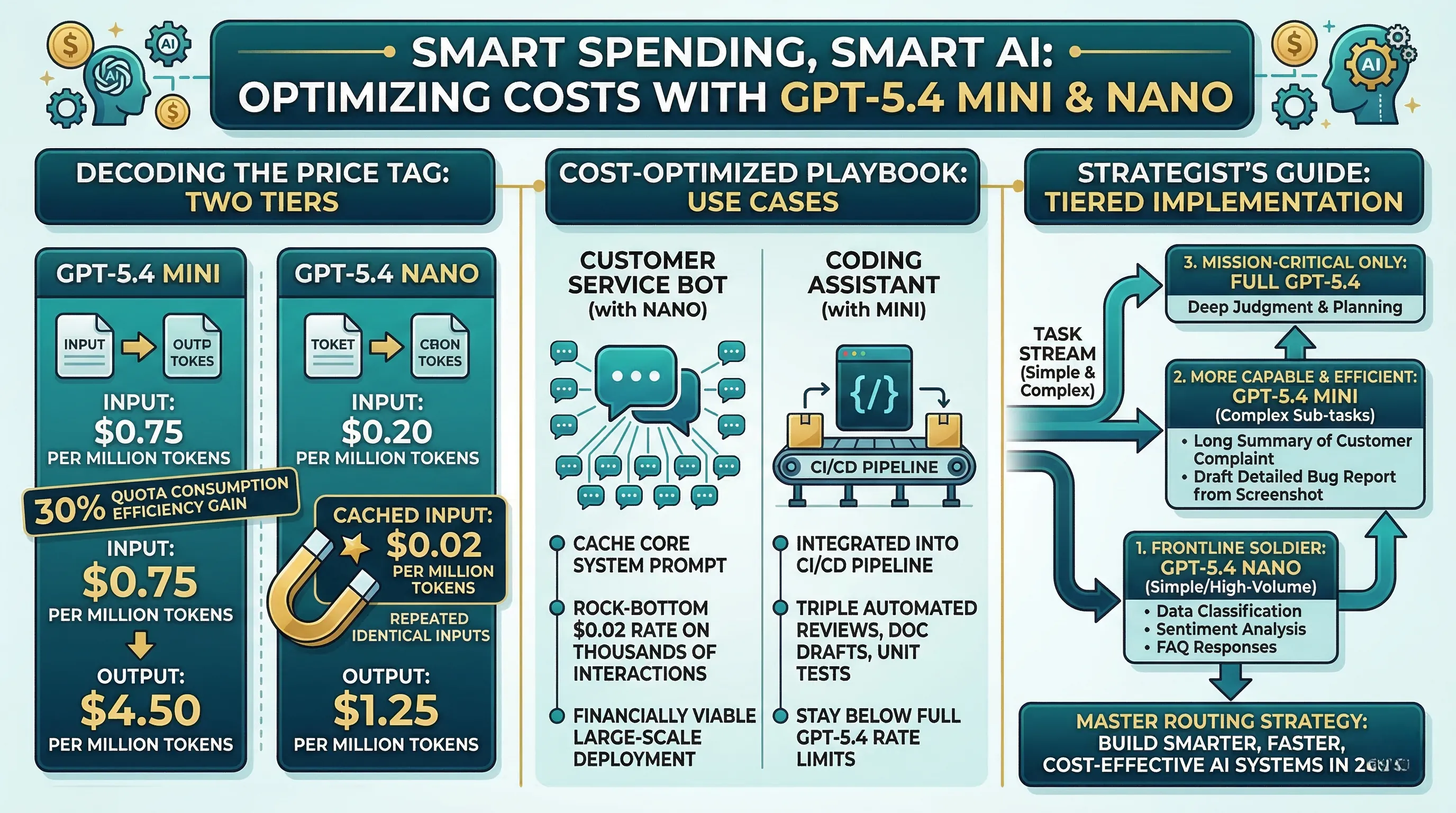
For GPT-5.4 mini, access via the Inworld Router sets the cost at $0.75 per million input tokens and $4.50 per million output tokens.
Crucially, it also features a massive efficiency gain, consuming only 30% of the standard GPT-5.4 quota for every call.
Meanwhile, GPT-5.4 nano establishes itself as the undisputed king of high-volume operations.
It boasts an astonishingly low price of $0.20 per million input tokens and $1.25 per million output tokens.
The secret weapon, however, is its cached input pricing, which plummets to just $0.02 per million tokens for repeated, identical inputs.
🔹 From Chatbots to Codebases: Your New Cost-Optimized Playbook
These numbers aren't just figures on a spreadsheet; they represent a fundamental shift in how you can architect your AI-driven applications.
Imagine deploying a customer service bot with GPT-5.4 nano.
You can cache its core system prompt—the instructions defining its personality and rules—and pay the rock-bottom $0.02 rate for it on thousands of subsequent user interactions, making large-scale deployment financially viable for the first time.
Now, consider a development team using GPT-5.4 mini as a coding assistant integrated into their CI/CD pipeline.
Because each API call only uses 30% of the quota, they can effectively triple their automated code reviews, documentation drafts, and unit test generations before hitting the same rate limits as the full GPT-5.4 model.
This isn't just about saving money; it's about unlocking a level of operational throughput that was previously reserved for the biggest enterprise budgets.
🔹 The Strategist's Guide to Tiered AI Implementation
The most common mistake will be to see this as an either/or choice.
The expert play is to build a multi-tiered workflow that leverages each model for its specific strengths.
Use GPT-5.4 nano as your frontline soldier, handling the massive volume of simple tasks like data classification, sentiment analysis, or FAQ responses.
Then, escalate more complex sub-tasks—like summarizing a long customer complaint for a human agent or drafting a detailed bug report from a screenshot—to the more capable and efficient GPT-5.4 mini.
This reserves your expensive, full-quota GPT-5.4 calls for only the most demanding tasks requiring deep judgment and planning.
Mastering this routing strategy is the key to building smarter, faster, and radically more cost-effective AI systems in 2026.
7. Ensuring Smooth Operations: A Look at GPT-5.4 Mini & Nano Reliability
🔹 The Unwritten Chapter of Errors
When reviewing initial documentation, we often look for the "gotchas"—the known limitations or common pitfalls that require workarounds.
However, for both GPT-5.4 Mini and GPT-5.4 Nano, the provided knowledge base is conspicuously silent on this front.
The official materials explicitly state that there are 'Cons: None explicitly stated' for either model.
Furthermore, no specific troubleshooting guides or lists of common operational errors have been provided, suggesting a clean bill of health right out of the gate.
🔹 The Implied Promise of Predictability
This lack of documented flaws translates into a powerful real-world benefit: operational confidence.
For a startup relying on GPT-5.4 Nano to handle thousands of simple, high-volume API requests per minute, this implies a system you can set and forget, minimizing the need for complex error-handling logic and reducing overhead.
Similarly, a developer using GPT-5.4 Mini as a critical component in a multi-model system can trust it to execute its subtasks—like scanning a codebase or drafting a pull request—without introducing instability into the larger workflow.
This isn't just about convenience; it's about building applications on a foundation you can trust, allowing you to focus on innovation rather than constant maintenance and firefighting.
🔹 An Expert's Read on the Clean Slate
While long-term, large-scale deployment will be the ultimate trial, this initial absence of stated cons is a very strong positive signal.
It suggests that both Mini and Nano have been engineered from the ground up for stability and have likely been rigorously stress-tested to eliminate common failure points before ever reaching the public.
Our expert take is that developers can integrate these models with a high degree of assurance, expecting consistent performance and uptime from day one.
The narrative here isn't about mitigating risk; it's about the sheer velocity you can achieve when your core tools are built to be this dependable.

8. 💡 Tech Talk: Making Sense of the Jargon
- Multimodal Reasoning: Imagine a chef who can not only read a recipe (text) but also understand how ingredients look (image), how they feel (tactile), and what steps to take based on a video demonstration (video). Multimodal Reasoning is when an AI model can do something similar – understanding and connecting information from different types of data, like text, images, and code, all at once.
- Tool Use: Think of an AI model as an apprentice who isn't just smart but can also pick up and use different tools – like a hammer, screwdriver, or measuring tape – to get a job done. Tool Use means the AI can intelligently interact with external programs or APIs (like using a calendar app, searching the web, or running a specific piece of code) to extend its capabilities beyond just talking.
- High-Volume API: Picture a super-efficient factory line designed to quickly produce millions of identical, simple items, like bottle caps. High-Volume API refers to an AI service specifically built to handle a massive number of requests very, very quickly and cheaply, often for straightforward, repetitive tasks without breaking the bank.
- Cached Input: Imagine you've asked a librarian for a specific book title before, and they keep a note of it so next time you ask for the *exact same book*, they can hand it to you instantly without searching. Cached Input is similar: when an AI processes the exact same query again, it can retrieve the previously processed (or "cached") result much faster and often at a lower cost because it doesn't have to re-compute everything from scratch.
📚 Related Posts
iPhone 17e vs. Galaxy S26: Which Flagship Upgrade is Right for You?
🚀 Key TakeawaysThe iPhone 17e promises exceptional value, packing the powerful A19 chip and a generous 256GB base storage into a more accessible price point, alongside the long-awaited inclusion of MagSafe.The Galaxy S26 series is set for a strong launc
tech.dragon-story.com
Samsung Galaxy S26 Ultra: Redefining Flagship with Next-Gen AI and Privacy Display
🚀 Key TakeawaysExperience a revolution with next-gen AI features powered by Smarter Galaxy AI and One UI 8.5, promising an efficient and user-friendly intelligent experience.Enjoy unparalleled visual fidelity and security with a Built-in Privacy Display
tech.dragon-story.com
Samsung T9 Portable SSD vs SanDisk Extreme Portable SSD – Speed Test & Comparison
🚀 Key TakeawaysUnrivaled Speed: The Samsung T9 and Crucial X10 Pro lead with read/write speeds up to 2,000MB/s and 2,100MB/s respectively, making them ideal for high-bandwidth tasks like 4K/8K video editing and large file transfers.Rugged Durability for
tech.dragon-story.com



