🚀 Key Takeaways
- DeepSeek-V4 revolutionizes the AI landscape by officially launching its open-source V4-Pro and V4-Flash models, spearheading the "1 Million Token Era" with unprecedented context length capabilities, robust cost-efficiency, and cutting-edge architectural innovations designed for advanced reasoning and agentic workflows.
DeepSeek has officially unveiled its groundbreaking DeepSeek-V4 series, comprising the powerful DeepSeek-V4-Pro and the efficient DeepSeek-V4-Flash models.
This release marks a significant milestone, ushering in the highly anticipated "1 Million Token Era" and setting a new benchmark for open-source large language models globally.
Launched on April 24, 2026, these models are now available for preview and officially live, promising to redefine the capabilities of AI in handling extensive information.
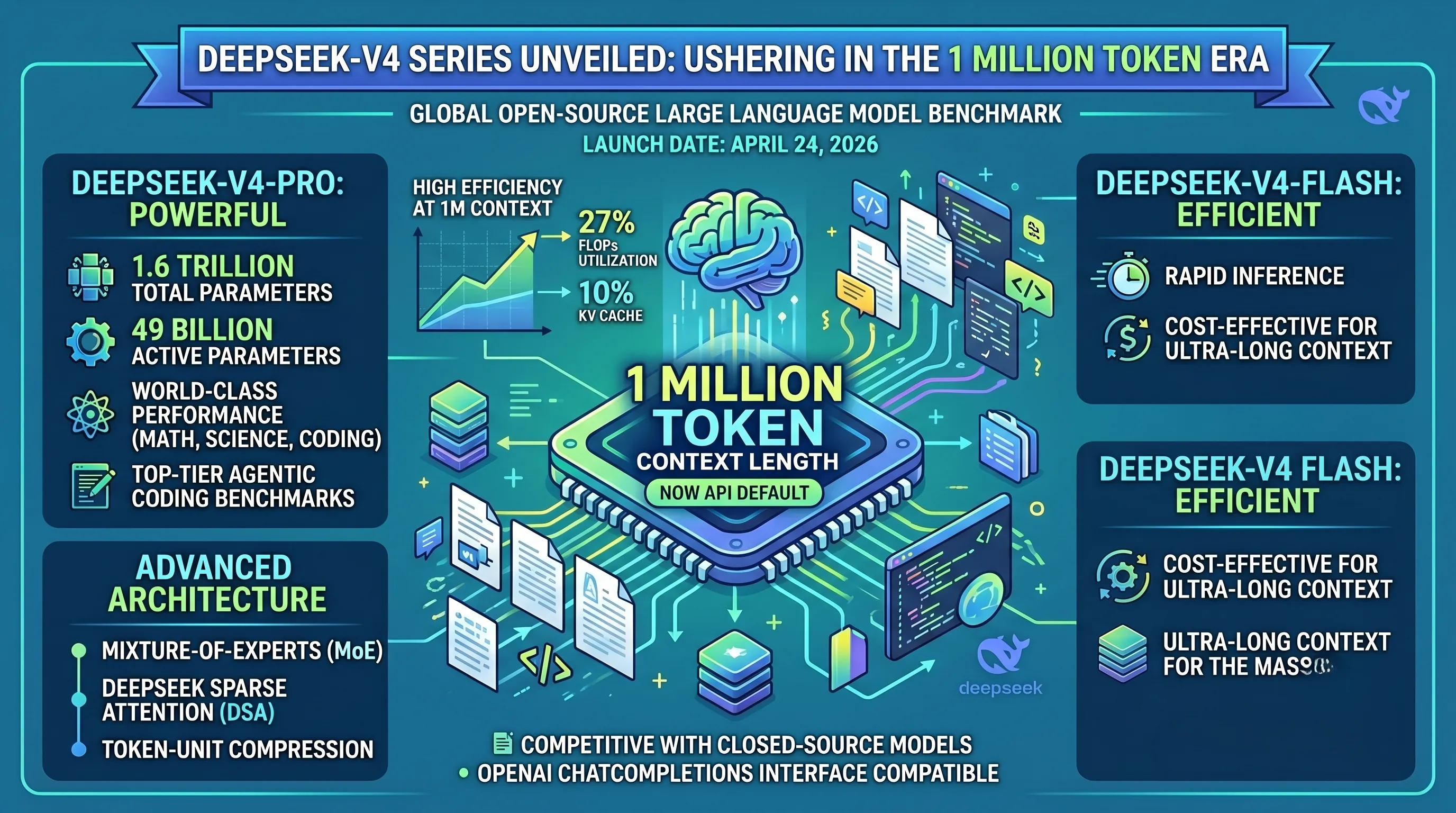
The centerpiece of the DeepSeek-V4 series is its extraordinary 1 million (1M) token context length, which is now the standard API default.
This massive context window empowers developers and researchers to tackle tasks previously deemed impossible, such as large-scale document analysis, sophisticated long-term memory-based AI applications, and intricate long-horizon agent workflows.
Beyond sheer capacity, DeepSeek-V4-Pro, with its 1.6 trillion total parameters (49 billion active), demonstrates remarkable efficiency, utilizing only 27% of FLOPs and 10% of KV cache at 1M context, making ultra-long context both powerful and cost-effective.
Leveraging advanced architectural innovations like Mixture-of-Experts (MoE), DeepSeek Sparse Attention (DSA), and token-unit compression technology, DeepSeek-V4-Pro delivers world-class performance, especially in areas like math, science, and coding.
It has achieved top-tier results in Agentic Coding benchmarks and is recognized for being competitive with some closed-source AI models.
DeepSeek aims to lead the cost-efficient ultra-long context AI market, providing robust API support accessible via the OpenAI ChatCompletions interface, and cementing its position as a game-changer for advanced AI development.
1. DeepSeek V4 Unveiled: Pioneering the Million-Token Era with Groundbreaking Architecture
The official announcement of DeepSeek V4 serves as the central pillar for the overarching theme, "DeepSeek V4 Unveiled, ‘The Million-Token Era’ Officially Begins."
This section provides a deep-dive analysis into the specific models, their groundbreaking architecture, and the performance metrics that transform the concept of a million-token context from a theoretical milestone into a practical reality for developers and researchers.
It is the technical foundation upon which the entire million-token era is being built, detailing precisely how DeepSeek has achieved this monumental feat of engineering.
The Official Release: Models, Date, and Accessibility
On 2026-04-24, DeepSeek AI officially launched its latest series of models, marking a pivotal moment in the evolution of large language models.
The release introduced two distinct versions: DeepSeek-V4-Pro and DeepSeek-V4-Flash.
Both models were made available immediately as a preview and are officially live, with the company committing to an open-source release, fostering wider community access and innovation.
This dual-model strategy caters to different user needs, with V4-Pro designed for maximum performance in complex reasoning and V4-Flash optimized for speed and efficiency.
Critically, accessing these powerful new models has been made exceptionally simple.
Both V4-Pro and V4-Flash are accessible via the DeepSeek API, which leverages the widely adopted OpenAI ChatCompletions interface.
This means that developers with existing integrations can switch to the new models simply by changing the model name in their API calls, dramatically lowering the barrier to adoption.
Architectural Pillars of the Million-Token Context
Achieving a stable and efficient one million (1M) token context window is not merely about scaling up existing designs; it requires a fundamental reimagining of model architecture to overcome immense computational and memory bottlenecks.
DeepSeek V4's success is built on a synergy of four key innovations.
Mixture-of-Experts (MoE): A Trillion-Parameter Brain with Focused Attention
At the core of DeepSeek-V4-Pro is a sophisticated Mixture-of-Experts (MoE) architecture.
While the model boasts a staggering 1.6 trillion total parameters, it only activates a fraction of these—49 billion active parameters—for any given token during inference.
This approach is akin to having a vast library of specialized experts (the "trillions" of parameters) but only consulting the most relevant ones (the "billions" of active parameters) for a specific question.
The result is a model that possesses the knowledge and nuance of a much larger dense model while maintaining the computational efficiency and speed of a smaller one, a crucial prerequisite for handling the demands of an ultra-long context.
DSA (DeepSeek Sparse Attention) & Hybrid Attention: Slaying the Quadratic Dragon
The primary obstacle to long context lengths in traditional transformer models is the self-attention mechanism, which has a computational and memory complexity that scales quadratically with the sequence length (O(n²)).
For a 1M token context, this becomes computationally prohibitive.
DeepSeek addresses this directly with its proprietary DSA (DeepSeek Sparse Attention) mechanism.
While specific details are proprietary, sparse attention techniques work by focusing computation only on the most relevant tokens instead of all possible token pairs, breaking the quadratic scaling law.
This is further enhanced by a Hybrid Attention system, which likely combines the strengths of different attention patterns—perhaps using dense, all-to-all attention for recent, local context and the highly efficient DSA for long-range dependencies across the entire 1M token window.
This dual approach ensures both local coherence and the ability to retrieve information from hundreds of thousands of tokens away without a catastrophic performance collapse.
Token-unit compression technology
The final piece of the architectural puzzle is token-unit compression technology.
This innovation effectively increases the amount of real-world information that can be packed into each token.
By creating a more efficient representation of text, the model can "read" and process significantly more content—such as entire codebases, lengthy legal documents, or comprehensive research papers—within its 1M token limit compared to models with less optimized tokenization schemes.
This directly enhances the practical utility of the vast context window.
Unprecedented Efficiency and Performance
The combination of these architectural innovations delivers not just a massive context length but a usable one.
The DeepSeek API sets the default context length to 1M tokens, a bold statement of confidence in the models' efficiency.
For the V4-Pro model operating at this full 1M context, the efficiency gains are dramatic.
It utilizes only 27% of the single-token inference FLOPs and a mere 10% of the KV cache usage that a conventional, non-optimized model of similar size would require.
In practical terms, this translates to significantly lower operational costs, faster response times, and the ability to run such large-scale analysis on less demanding hardware, making the million-token era not just a technical possibility but an economically viable one.

2. Redefining AI Performance and Efficiency in Ultra-Long Contexts
The launch of DeepSeek V4, heralding the "1M Token Era," is not merely a quantitative leap but a fundamental redefinition of what is computationally possible and economically viable in AI.
This new era is built upon the groundbreaking performance and efficiency of models like DeepSeek V4-Pro, which directly addresses the historical bottlenecks that made ultra-long context windows impractical for widespread use.
The ability to process 1 million tokens is one thing; doing so efficiently is the true revolution that DeepSeek V4-Pro spearheads.
Breaking the Computational Barrier: Unprecedented Resource Savings
At the heart of DeepSeek V4-Pro's contribution to the 1M token era is its radical structural innovation, designed specifically to tackle the punishing computational and memory costs associated with the attention mechanism in massive contexts.
The results are staggering and set a new industry benchmark.
According to official data, when processing a 1M token context, the model's single-token inference requires only 27% of the FLOPs (Floating Point Operations Per Second) compared to conventional approaches.
This is not an incremental improvement; it is a transformative reduction in computational workload, directly translating to lower energy consumption and significantly reduced hardware requirements.
Even more critically, the model's KV cache usage plummets to just 10% of what would typically be required.
The KV cache is the primary memory bottleneck in long-context LLMs, often demanding vast amounts of expensive VRAM.
By shrinking this footprint so dramatically through technologies like DSA (DeepSeek Sparse Attention) and Hybrid Attention, DeepSeek V4-Pro makes it feasible to run 1M context operations on a wider range of hardware, democratizing access to this powerful capability.
This efficiency is the very engine that makes the 1M token era a commercial reality rather than a theoretical milestone.
World-Class Performance in High-Stakes Domains
Efficiency without performance would be an empty victory.
DeepSeek V4-Pro demonstrates that its resource-saving architecture does not come at the cost of intellectual prowess.
The model delivers world-class performance among open-source models, particularly in specialized and complex domains like math, science, and coding.
Its ability to maintain high-fidelity reasoning over vast stretches of information allows it to tackle problems that were previously intractable.
This powerful reasoning capability positions DeepSeek V4-Pro as a direct competitor to some of the leading closed-source AI models.
Its strong performance is particularly evident in benchmarks for agentic coding, where it has achieved top-tier results.
This proves that the model can not only ingest and recall information from a million-token context but can also actively reason, plan, and execute complex tasks based on that information, a critical requirement for sophisticated AI applications.
Unlocking New Frontiers: From Document Analysis to Advanced AI Agents
The combination of massive context, extreme efficiency, and powerful reasoning unlocks a new tier of applications, firmly establishing the practical value of the 1M token era.
The new standard set by DeepSeek V4-Pro for cost-effective ultra-long context directly facilitates:
- Large-Scale Document Analysis:
Professionals can now analyze entire research anthologies, complex legal discovery documents, or massive codebases in a single, coherent session, asking nuanced questions that require a holistic understanding of the entire dataset. - Long-Term Memory-Based AI:
AI assistants and chatbots can now possess a truly long-term memory, retaining the full context of conversations spanning days or weeks. This leads to more personalized, intelligent, and contextually aware interactions without cumbersome and error-prone summarization techniques. - Advanced Agentic Workflows:
The model is explicitly designed for long-horizon agent workflows. Its 1M token window serves as an expansive "scratchpad" for complex planning and reasoning, while its efficiency ensures faster response times. This enhanced integration with AI agent development environments makes it possible to build more capable and responsive agents that can execute multi-step tasks requiring deep context and strategic foresight.
By delivering a 1M token context that is not only powerful but also affordable and fast, DeepSeek V4-Pro is actively building the infrastructure for the next generation of AI, truly kicking off an era where the only limit is the complexity of the problems we choose to solve.

3. Navigating the Frontiers: DeepSeek V4's Current Performance Nuances and Challenges
While the launch of DeepSeek V4 undeniably signals the beginning of the ‘1 Million Token Era’, a deeper analysis of its current performance reveals the complex challenges that accompany such a monumental leap in context length.
This section directly connects to the main topic by providing a crucial, grounded perspective: achieving a 1M token capacity is a historic milestone, but fully and reliably harnessing that capacity across all tasks presents the next frontier of challenges.
These nuances do not diminish the achievement but rather offer a transparent look at the model's current state, setting realistic expectations for developers and researchers on the cutting edge.
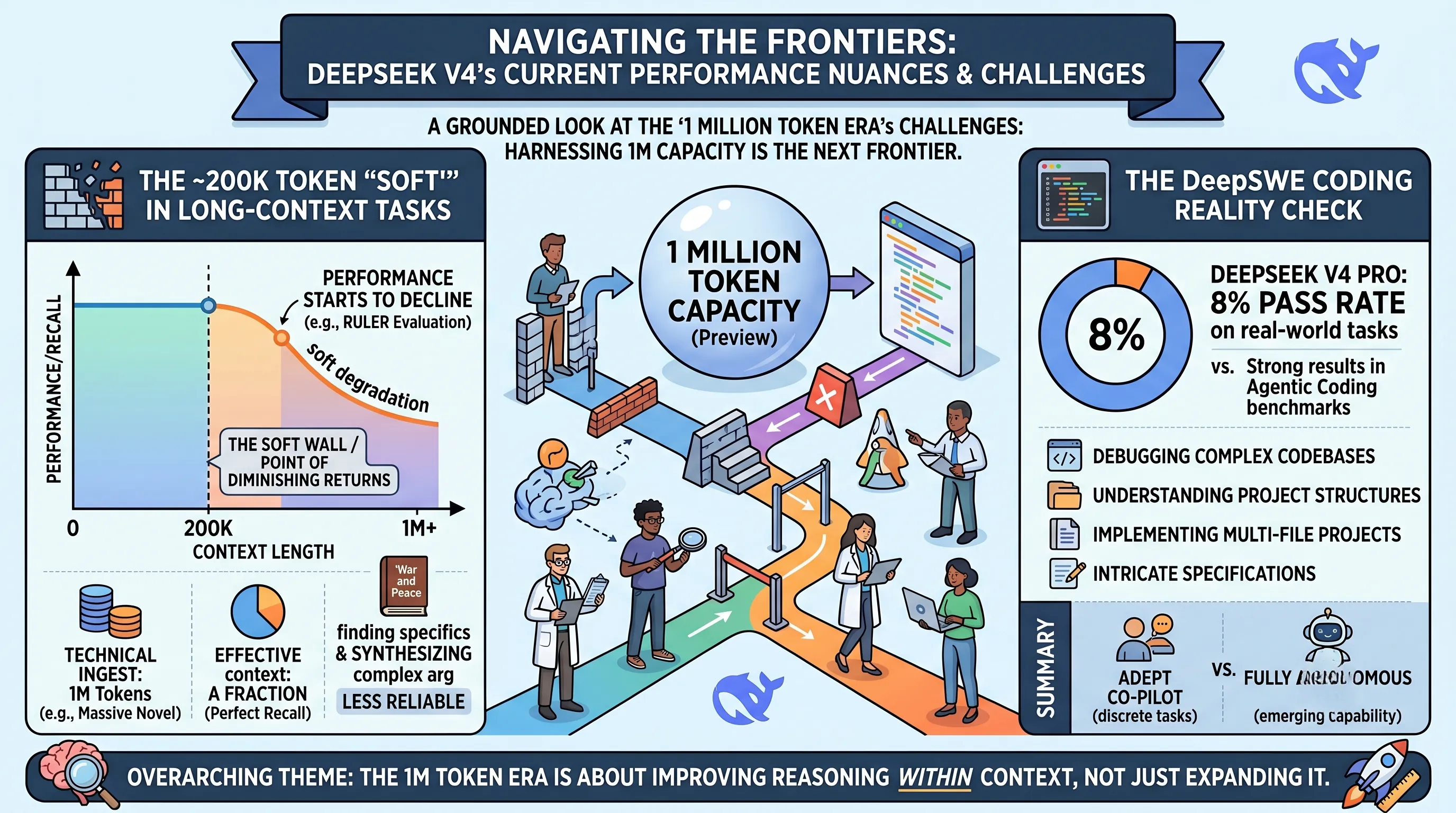
The ~200K Token "Soft Wall" in Long-Context Tasks
A primary selling point of DeepSeek V4 is its ability to process a staggering 1 million tokens, a capability that promises to revolutionize large-scale document analysis and long-term AI memory.
However, initial benchmark results provide a more textured picture of this capability in its current "Preview" stage.
According to the provided data, DeepSeek V4 Pro exhibits some performance degradation once the context length extends past approximately 200,000 tokens.
This was observed in rigorous long-context evaluations like RULER, which are specifically designed to test a model's ability to recall and reason over vast amounts of information.
Experientially, this isn't a hard crash but more of a "soft wall" or a point of diminishing returns.
For a user, this means that while the model can technically ingest a 1M token document—the equivalent of a massive novel like "War and Peace"—its ability to flawlessly find a specific detail or synthesize complex arguments from the latter parts of that document might become less reliable after the 200K mark.
It suggests that the model's effective, high-fidelity context window for the most demanding tasks currently sits at a fraction of its theoretical maximum.
This is a critical nuance for anyone planning to build applications that rely on perfect recall across the entire million-token spectrum.
A Sobering Metric: The DeepSWE Coding Benchmark
DeepSeek V4 Pro is rightly praised for its strong performance in coding, math, and science, even achieving top-tier results in several Agentic Coding benchmarks.
This positions it as a powerful tool for developers.
However, to provide a fully balanced perspective, it is essential to consider more challenging, real-world evaluations.
The DeepSWE benchmark results offer precisely this kind of reality check.
In this specific software engineering benchmark, DeepSeek V4 Pro was found to pass only 8% of the assigned tasks.
This 8% pass rate does not invalidate its other impressive coding scores; rather, it highlights the immense difficulty of real-world, end-to-end software engineering problems.
Benchmarks like DeepSWE often involve more than just writing a function; they can include debugging complex codebases, understanding large project structures, and implementing features based on intricate specifications.
This result indicates that while DeepSeek V4 Pro is an adept coder for discrete tasks, its ability to act as an autonomous software engineer on complex, multi-file projects is still an emerging capability.
For developers, this means the model is a world-class co-pilot for many tasks but not yet a fully autonomous pilot for navigating the complexities of a large, existing software project.
These findings underscore that the journey into the 1M token era is as much about improving reasoning and task completion within that context as it is about simply expanding the window itself.
📚 Related Posts
TRELLIS.2: O-Voxel AI Revolutionizes 3D Generation with Unprecedented Speed, Hyper-Realism & Democratized Access – Full Releas
🚀 Key TakeawaysTRELLIS.2 revolutionizes 3D generation with its innovative O-Voxel technology, enabling the creation of highly complex, thin, and hollow structures with exceptional detail and realism.This 4B-parameter image-to-3D model offers unprecedent
tech.dragon-story.com
Microsoft Copilot: The Agentic AI Colleague Revolutionizing Productivity & Delivering 353% ROI Across Microsoft 365
🚀 Key TakeawaysMicrosoft Copilot is fundamentally ushering in the 'AI Colleague' era, transforming how work is done across productivity tools like Word, Excel, and PowerPoint by enabling agent-type AI functionality that performs complex multi-step tasks
tech.dragon-story.com
Claude AI's 'Connector' Transforms Daily Life: 200+ App Integrations Redefine Productivity & Trust
🚀 Key TakeawaysClaude's latest evolution, driven by the innovative 'Connector' function, profoundly integrates advanced AI into daily life by seamlessly linking with over 200 everyday applications, enabling users to manage complex, multi-step tasks with
tech.dragon-story.com



