Key Takeaways: DreamDojo - A New Era for Robot Learning
- Paradigm Shift: DreamDojo moves robot learning from task-specific data to large-scale, unlabeled human video pre-training, enabling strong zero-shot generalization.
- Core Architecture: It leverages a Spatio-Temporal Transformer that learns world dynamics through a self-supervised masked prediction objective.
- Resource Intensive: Replicating full DreamDojo pre-training requires significant GPU compute (e.g., 8x A100/H100s), though inference is possible on a single high-end consumer GPU.
- MPC for Control: DreamDojo-Control utilizes Model Predictive Control (MPC) to 'dream' future states and select optimal actions based on the learned world model.
- Challenges Ahead: Addressing scalability, safety (learning from human video), simulation-to-reality gap, and ethical concerns are crucial for widespread adoption.
The field of robotics is constantly evolving, and a significant stride forward is evident in DreamDojo, a novel generalist robot world model described in the February 2026 paper, arXiv:2602.06949v1.
This advanced model redefines robot learning by skillfully leveraging vast quantities of unlabeled human video data to understand world dynamics.
This guide will walk you through DreamDojo's architecture, setup, and application, providing you with the knowledge to begin your own experiments with this groundbreaking approach.
The Paradigm Shift: Why DreamDojo's Generalist Approach Outperforms Legacy Robot Learning
For many years, robot learning has faced a fundamental hurdle: data scarcity.
Traditional methods, such as imitation learning and reinforcement learning, demand extensive amounts of data tailored to specific tasks and domains.
This data often comes from costly robot teleoperation or millions of simulation trials, leading to models that excel at one specific task but struggle with even minor variations.
DreamDojo offers a fresh perspective.
Instead of relying on expensive robot-specific data, it develops a foundational understanding of physics, object interactions, and human intentions by pre-training on massive, unlabeled human video datasets.
This acquired knowledge facilitates remarkable zero-shot generalization, allowing a robot to perform tasks it has never been explicitly trained to do.
Comparison: Legacy Robot Learning vs. DreamDojo
| Feature | Legacy Robot Learning (e.g., RL, Imitation Learning) | DreamDojo (Generalist World Model) |
|---|---|---|
| Primary Data Source | Task-specific robot data (teleoperation, simulation) | Large-scale, diverse human videos (e.g., Ego4D) |
| Data Requirement | Extremely high for each new task; data is expensive. | Massive upfront pre-training, but cheap, abundant data. |
| Task Specificity | High. Models are brittle and specialized. | Low. A single model can be applied to many tasks. |
| Generalization | Poor. Fails with novel objects or environments. | High. Strong zero-shot capabilities for unseen tasks. |
| Training Method | Supervised learning or reward-based optimization. | Self-supervised pre-training (masked prediction). |
| Core Capability | Learns a direct policy (state -> action). | Learns a world model (predicts future states). |
This transition from learning a specific policy to developing a universal world model is DreamDojo's core innovation.
It enables the robot to 'imagine' the outcomes of its actions, facilitating robust planning and control without the need for task-specific fine-tuning.
Setting Up Your DreamDojo Lab: Essential Hardware, Software & Data for 2026
Replicating or building upon the DreamDojo research requires a substantial computational setup.
Here are the recommended components as of early 2026.
Hardware Requirements
- Pre-training (High-End):
- GPUs: A multi-node setup with at least 8x NVIDIA A100 (80GB) or H100 GPUs is recommended.
The original research cites this configuration for training the full-scale model.
Memory capacity is vital for handling large batch sizes and long video sequences. - CPU: High core-count server-grade CPUs (e.g., AMD EPYC, Intel Xeon) are needed for efficient data loading and preprocessing.
- Storage: Several terabytes of fast NVMe SSD storage are required to manage massive video datasets without I/O bottlenecks.
- GPUs: A multi-node setup with at least 8x NVIDIA A100 (80GB) or H100 GPUs is recommended.
- Inference/Deployment (Minimum):
- GPU: A single high-end consumer or workstation GPU like an NVIDIA RTX 4090 (24GB) or a newer 50-series equivalent may be sufficient for running inference and zero-shot control with the pre-trained model.
However, performance will be slower compared to multi-GPU setups.
- GPU: A single high-end consumer or workstation GPU like an NVIDIA RTX 4090 (24GB) or a newer 50-series equivalent may be sufficient for running inference and zero-shot control with the pre-trained model.

Software Stack
- Deep Learning Framework:
The original implementation is built on PyTorch.
Familiarity with the PyTorch ecosystem, includingtorch.distributedfor multi-GPU training, is essential. - Robotics Middleware:
ROS 2 (Robot Operating System) is the standard for integrating with a wide array of physical and simulated robots.
You will need ROS 2 client libraries for Python (rclpy) to bridge DreamDojo's outputs with robot controllers. - Simulation Environment:
NVIDIA Isaac Sim is highly recommended due to its realistic physics and seamless integration with deep learning workflows.
It serves as a powerful tool for safely testing DreamDojo's control policies before deployment on physical hardware.
Data Considerations
DreamDojo's effectiveness stems from its data.
You will need to access or curate large-scale human video datasets.
Key examples utilized in the research include:
- Ego4D: A massive, diverse egocentric video dataset.
- Something-Something-v2: A dataset specifically focused on human-object interactions.
- Epic-Kitchens: Long-form egocentric videos of kitchen activities.
Accessing these datasets typically requires agreeing to their respective license terms.
Preprocessing these videos involves significant computational effort to extract frames and tokenize them for the model's input.
Decoding DreamDojo's Brain: An In-Depth Look at its Transformer World Model
At the heart of DreamDojo lies a Spatio-Temporal Transformer.
This architecture is specifically designed to comprehend not just the content of individual images, but also the dynamics of how the world changes over time.

Key Architectural Components
- Video Tokenization:
Much like how Vision Transformers (ViT) process static images, DreamDojo first breaks down a video into a sequence of discrete tokens.
Each frame is divided into non-overlapping patches, and each patch is then linearly embedded.
This process generates a sequence of visual tokens, each representing a segment of the scene at a particular time step. - Multimodal Fusion:
DreamDojo operates as a multimodal model, integrating several input streams into a unified representation space.
These streams include:
- Visual Tokens: The patch embeddings derived from the video frames.
- Proprioceptive Tokens: The robot's own state information (e.g., joint angles, gripper position), which are projected into the same embedding dimension.
- Language Tokens (Optional): A text prompt detailing the goal (e.g., "pick up the red block") is encoded using a standard text encoder and treated as another sequence of tokens.
- Spatio-Temporal Transformer Backbone:
The combined sequence of tokens is then fed into a large Transformer model.
The self-attention mechanism within this Transformer enables the model to learn intricate relationships between different objects in a scene (spatial reasoning) and how these relationships evolve over time (temporal reasoning).
This is how the model develops an intuitive grasp of physical laws. - Self-Supervised Pre-training Objective:
The model is trained without the need for human labels.
Its primary objective is a masked autoencoding task.
During training, a substantial percentage of the input tokens (for instance, 75% of video patches) are randomly masked.
The model's task is to predict the original content of these masked tokens based solely on the surrounding context.
By learning to 'fill in the blanks' within a video sequence, it is compelled to develop a deep, predictive understanding of the world's dynamics.
Your First DreamDojo Robot: A Step-by-Step Guide to Pre-training and Zero-Shot Control
This guide outlines the conceptual workflow for conducting a basic DreamDojo experiment.
Don't worry if it seems complex at first; breaking it down into steps makes it manageable.
Step 1: Data Preparation
- Acquire Data:
Start by downloading a relevant human video dataset, such as a subset of Something-Something-v2. - Pre-process:
You'll need to write scripts to extract frames from these videos at a consistent frame rate (e.g., 10 frames per second).
Ensure frames are normalized and resized to match the model's expected input resolution. - Tokenize:
Implement the patching and embedding logic to convert your sequences of frames into numerical token sequences that are ready for model input.

Step 2: Pre-train the World Model
- Configure Training:
Set up your distributed training script using PyTorch'sDistributedDataParallelto leverage multiple GPUs. - Instantiate Model:
Define the Spatio-Temporal Transformer architecture within your code, matching the specifications from the research paper. - Implement Masking:
Create a data loader that intelligently applies the random masking strategy to your tokenized video batches. - Launch Training:
Initiate the self-supervised pre-training process on your multi-GPU hardware.
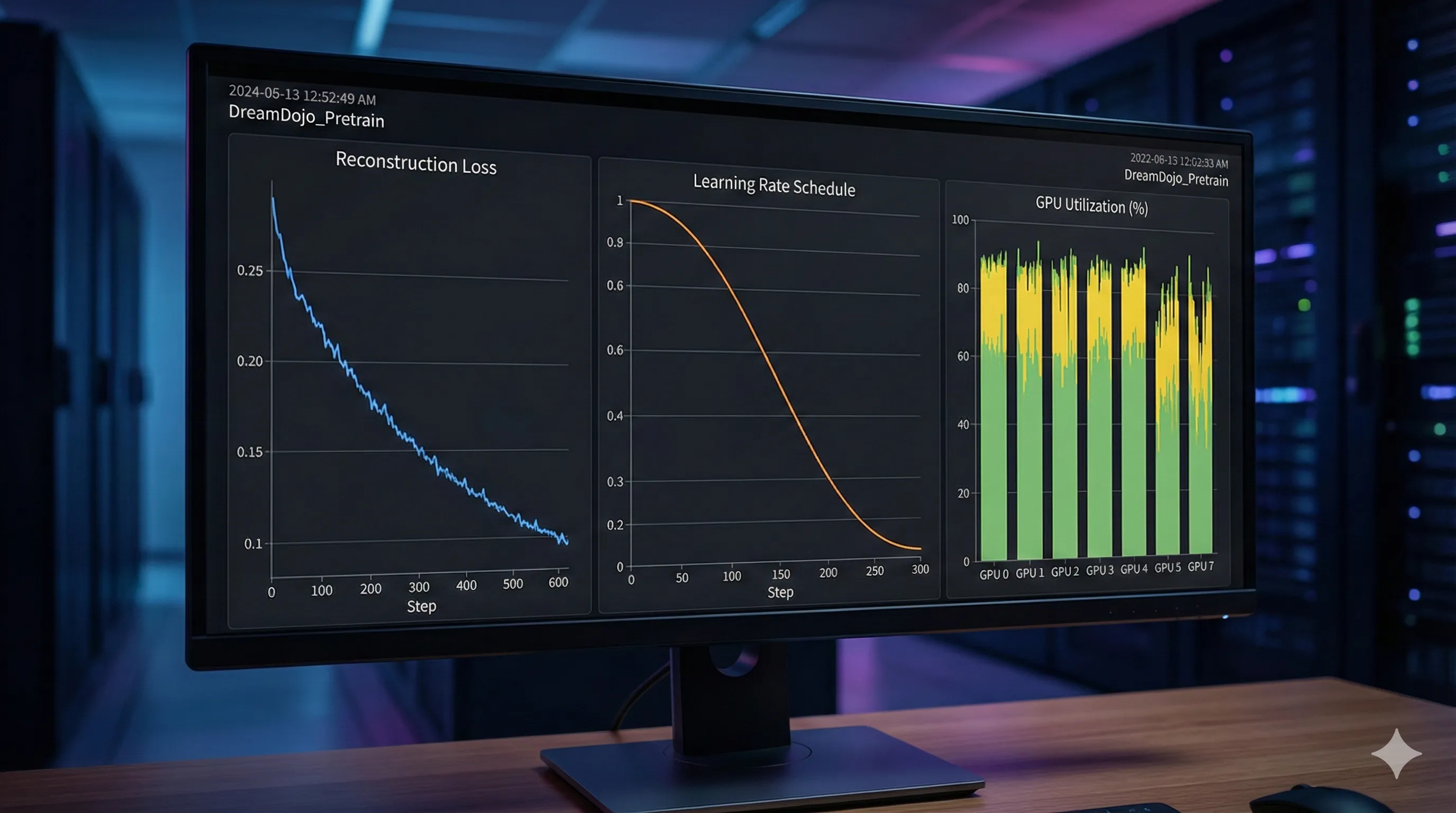
Be prepared, as this is the most computationally intensive step and can span days or even weeks. - Monitor:
Diligently track the reconstruction loss.
As the loss decreases, it signifies that the model is improving its ability to accurately predict the masked video content.
Step 3: Set Up the Control Loop (DreamDojo-Control)
- Load Pre-trained Model:
Once pre-training is complete, load the learned weights into your world model. - Define Task:
Clearly specify the robot's goal, which can be provided either as an image of the desired final state or a concise language command like "open the drawer." - Implement Planner:
Integrate a planning algorithm such as Model Predictive Control (MPC).
This planner uses the world model to 'simulate' multiple short sequences of actions. - Execute Best Action:
The planner then selects the action sequence that is predicted to bring the robot closest to the defined goal state.
The robot executes only the very first action from this chosen sequence. - Repeat:
The robot observes its new state in the world, and the planning process repeats, forming a continuous, closed-loop control system.

Step 4: Zero-Shot Deployment
- Connect to Robot/Sim:
Use ROS 2 or a direct simulator API (like Isaac Sim's) to send the chosen actions to your physical robot or simulated environment.
Also, ensure you are receiving its proprioceptive state and camera feed. - Run:
Execute the control loop on a task the model has genuinely never encountered during its training.
For instance, if it was trained on general human interaction videos, you can now command it to stack blocks or wipe a table and observe its zero-shot performance.

Navigating DreamDojo Challenges: Common Pitfalls and Debugging Strategies
Working with large-scale models like DreamDojo inevitably presents unique challenges.
It's normal to encounter hurdles, and knowing how to debug them will save you significant time.
Challenge: GPU Memory Errors (CUDA out of memory)
- Cause:
Large models, extended video sequences, and high-resolution images can consume immense amounts of VRAM, leading to these errors. - Solution:
- Reduce Batch Size: This is often the simplest immediate fix, though it might slow down training convergence.
- Gradient Accumulation: Instead of updating weights after every batch, process several smaller batches and accumulate their gradients before performing a single weight update.
- Model Parallelism: For exceptionally large models, you might need to split the model's layers across multiple GPUs.
- Mixed-Precision Training: Utilize libraries such as PyTorch's
torch.cuda.ampto perform computations in FP16/BF16, which can significantly reduce memory usage without a major loss in accuracy.
- Reduce Batch Size: This is often the simplest immediate fix, though it might slow down training convergence.
Challenge: Slow or Unstable Pre-training
- Cause:
This can stem from an incorrect learning rate, poor weight initialization, or issues within your dataset pipeline. - Solution:
- Learning Rate Scheduler: Implement a learning rate scheduler with a warm-up phase (e.g., a linear warm-up followed by cosine decay) to help stabilize early training.
- Check Data Pipeline: Ensure your data loading process is not creating a bottleneck.
Profile your data loader and consider using multiple worker processes to speed it up. - Visualize Reconstructions: Periodically, have the model attempt to reconstruct a masked video from your validation set.
If the reconstructions are nonsensical or blurry, it strongly suggests a fundamental issue in the model architecture or the training loop itself.
- Learning Rate Scheduler: Implement a learning rate scheduler with a warm-up phase (e.g., a linear warm-up followed by cosine decay) to help stabilize early training.
Challenge: Unexpected Robot Behavior in Zero-Shot Control
- Cause:
The world model's predictions are inherently imperfect, and the inherent gap between the diversity of human videos and the specific robot's morphology (its physical shape and capabilities) can lead to flawed plans. - Solution:
- Debug the Plan: Visualize the future states that the world model predicts.
Is the model 'hallucinating' impossible physics or outcomes?
This visual inspection can be invaluable for understanding why it chose a particular action. - Adjust Planning Horizon: A shorter MPC horizon might lead to more reactive and potentially safer behavior, which is useful for delicate tasks.
Conversely, a longer horizon might be necessary for executing more complex, multi-step tasks. - Goal Specification: Ensure that your goal (whether an image or a text command) is unambiguous and clearly defined.
A vague goal can unfortunately lead the planner to a valid but undesired local minimum.
- Debug the Plan: Visualize the future states that the world model predicts.

Integrating DreamDojo with Modern Robotics Frameworks: ROS, Isaac Sim & Beyond
DreamDojo's 'brain' requires a 'body' to manifest its capabilities in the real or simulated world.
Integrating it seamlessly with standard robotics frameworks is a crucial step for practical applications.
Integration with ROS 2
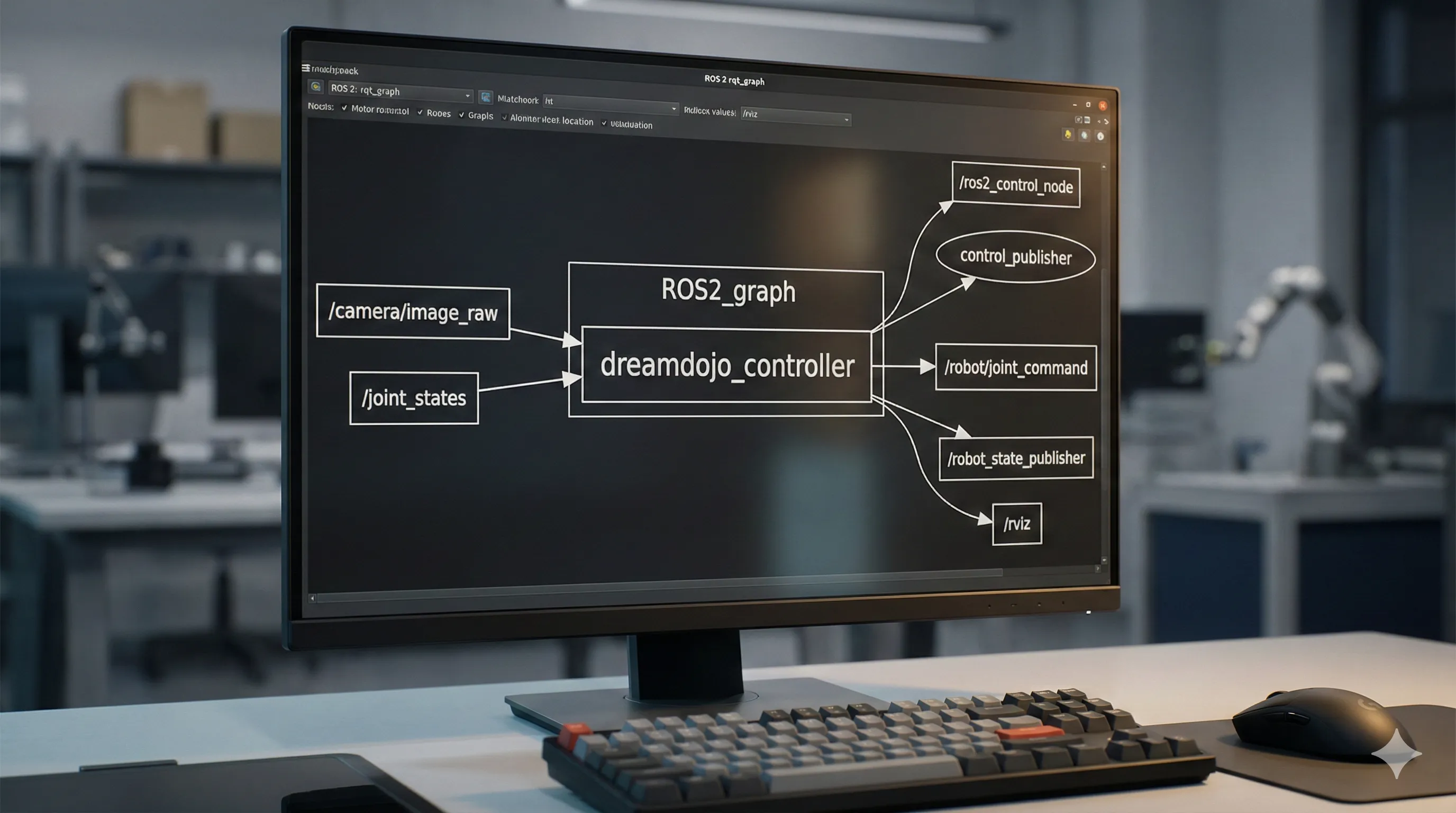
You can create a dedicated ROS 2 node in Python that acts as a host for the DreamDojo model and its MPC planner.
- Subscribers:
This ROS 2 node should subscribe to relevant topics that provide real-time robot observations, such as camera images (usingsensor_msgs/Image) and joint states (usingsensor_msgs/JointState). - Publishers:
After the MPC planner determines the optimal action, the node publishes these commands to the robot's low-level controller topics (e.g.,trajectory_msgs/JointTrajectoryfor precise joint movements orgeometry_msgs/Twistfor velocity control).
This decoupled architecture allows you to run the computationally intensive DreamDojo node on a powerful machine equipped with GPUs, while the robot's low-level controllers can operate on its integrated hardware or an embedded system.
Integration with NVIDIA Isaac Sim
NVIDIA Isaac Sim provides a powerful Python scripting interface that can directly import PyTorch models.
- You can run the entire control loop within a single Isaac Sim script.
This script would retrieve observations (such as camera renders and current robot states) directly from the simulator. - These observations are then fed into the DreamDojo model.
- The model computes the next action via MPC.
- Finally, the script applies that computed action directly to the simulated robot's joints or actuators—all contained within the Isaac Sim environment.
This integrated approach is ideal for rapid prototyping, iteration, and debugging of your control logic before you attempt to transfer it to a physical robot, minimizing potential risks and hardware wear.

Advanced Robot Planning with DreamDojo-Control: Implementing MPC for Complex Tasks
DreamDojo-Control is the sophisticated planning and control algorithm that effectively leverages the insights from the pre-trained world model.
Its core mechanism is Model Predictive Control (MPC).
How MPC with DreamDojo Works
- Observe Current State:
The robot continuously captures its current camera view and retrieves its proprioceptive readings (e.g., joint angles, gripper force). - Generate Candidate Action Sequences:
A set of potential short action sequences (e.g., a series of 10 joint velocity commands) is generated.
These sequences can be random or optimized based on previous steps. - Predict Future States (The 'Dream'):
For each candidate action sequence, the DreamDojo world model is used autoregressively.
It takes the current state and the first action to predict the next state.
Then, it uses that predicted state and the second action to predict the state after that, and so on.
This process effectively 'rolls out' an entire predicted future trajectory for each action sequence. - Evaluate Trajectories:
Each of these predicted trajectories is then rigorously evaluated against the defined goal.
For an image-based goal, the evaluation function might calculate the pixel-wise difference between the final predicted frame and the target goal image. - Select and Execute:
The action sequence that is predicted to lead to the most favorable future (closest to the goal) is chosen.
Crucially, the robot executes only the first action from this optimal sequence. - Repeat:
The entire process, from observing the current state (step 1), is repeated at every control step.
This continuous re-planning based on real-world feedback makes the system highly robust to minor errors and unexpected environmental changes.
For more complex, multi-step tasks (e.g., "open the microwave, then put the cup inside"), you can chain goals together.
Once the MPC controller successfully achieves the first sub-goal (e.g., confirming the "microwave is open"), the system can seamlessly transition to pursuing the next objective.

The Road Ahead for DreamDojo: Addressing Scalability, Safety, and Ethical Concerns
While DreamDojo represents a monumental leap forward in generalist robotics, its path to widespread adoption comes with several significant challenges that need to be addressed.
Scalability
The computational resources currently required for pre-training DreamDojo are immense, effectively limiting this research to large, well-funded laboratories.
Future research will need to concentrate on developing more efficient model architectures and innovative training techniques to make these powerful world models accessible to a broader community of researchers and developers.
Safety
Learning from vast amounts of human video data is a dual-edged sword.
The model might inadvertently learn unsafe or undesirable behaviors present in the training data, such as slamming a drawer or handling a knife carelessly.
A critical area of ongoing research involves developing robust methods to constrain the model's behavior and ensure it consistently adheres to predefined safety protocols, often referred to as 'Constitutional AI' or 'guardrails' for autonomous robotics.
Simulation-to-Reality Gap
Even though the model learns a general understanding of physics, subtle differences in a real robot's specific dynamics, sensor characteristics, and actuator responses can still pose considerable challenges.
Bridging this 'sim2real' gap—or, more accurately in this context, the 'human-video-to-robot-reality' gap—remains an active and vital area of research.
Ethical Considerations
- Data Provenance:
The use of internet-scale video data raises important questions concerning copyright, individual privacy, and the consent of the people depicted in the videos. - Bias:
A model trained predominantly on videos from one specific culture or demographic may unfortunately not generalize well, or could even exhibit unintended biases, when deployed in a different cultural context. - Autonomy:
As generalist robots become increasingly capable, society must engage in thoughtful discussion and grapple with the profound ethical implications of deploying highly autonomous systems in sensitive environments such as homes, workplaces, and public spaces.
DreamDojo is more than just a new model; it represents a new blueprint for constructing intelligent and adaptable robots.
By proactively addressing these complex challenges, the research community can unlock the full potential for truly general-purpose robots that are capable of learning, adapting, and providing meaningful assistance in the real world.



