🚀 Key Takeaways
- Gemini 3.1 Flash-Lite emerges as the most cost-efficient and ultra-fast Gemini model, optimized for high-volume, short-latency AI applications. It boasts up to 2.5x faster response start speeds and 45% faster output, with an input token price that is 1/10th of GPT-5.4, making high-quality AI more accessible and performant for developers and enterprises.
Introducing Gemini 3.1 Flash-Lite, Google's latest breakthrough in large language models, engineered for unparalleled speed and remarkable cost efficiency.
This powerful new model is specifically tailored for developers and enterprises dealing with high-volume workloads and requiring support for large-scale traffic, delivering a new standard in AI performance without compromising your budget.
It proudly stands as the most economical offering within the Gemini model family, embodying true "cost-effective AI" by merging superior quality with lightning-fast processing.
The performance metrics of Gemini 3.1 Flash-Lite are truly impressive, showcasing response start speeds up to 2.5 times faster and output generation that is 45% quicker than existing models.
It is meticulously optimized for cost-sensitive environments, high-volume LLM traffic, and critical short-latency use cases, making it the ideal choice for real-time service construction, extensive translation projects, comprehensive content review, and innovative UI generation or simulation design.
A notable innovation is its "Thinking Level function," which provides developers with the flexibility to adjust inference levels, perfectly balancing computational cost with desired performance for diverse tasks.

1. Flash-Lite's Core: Unpacking the Engine of Blazing Speed and Unrivaled Efficiency
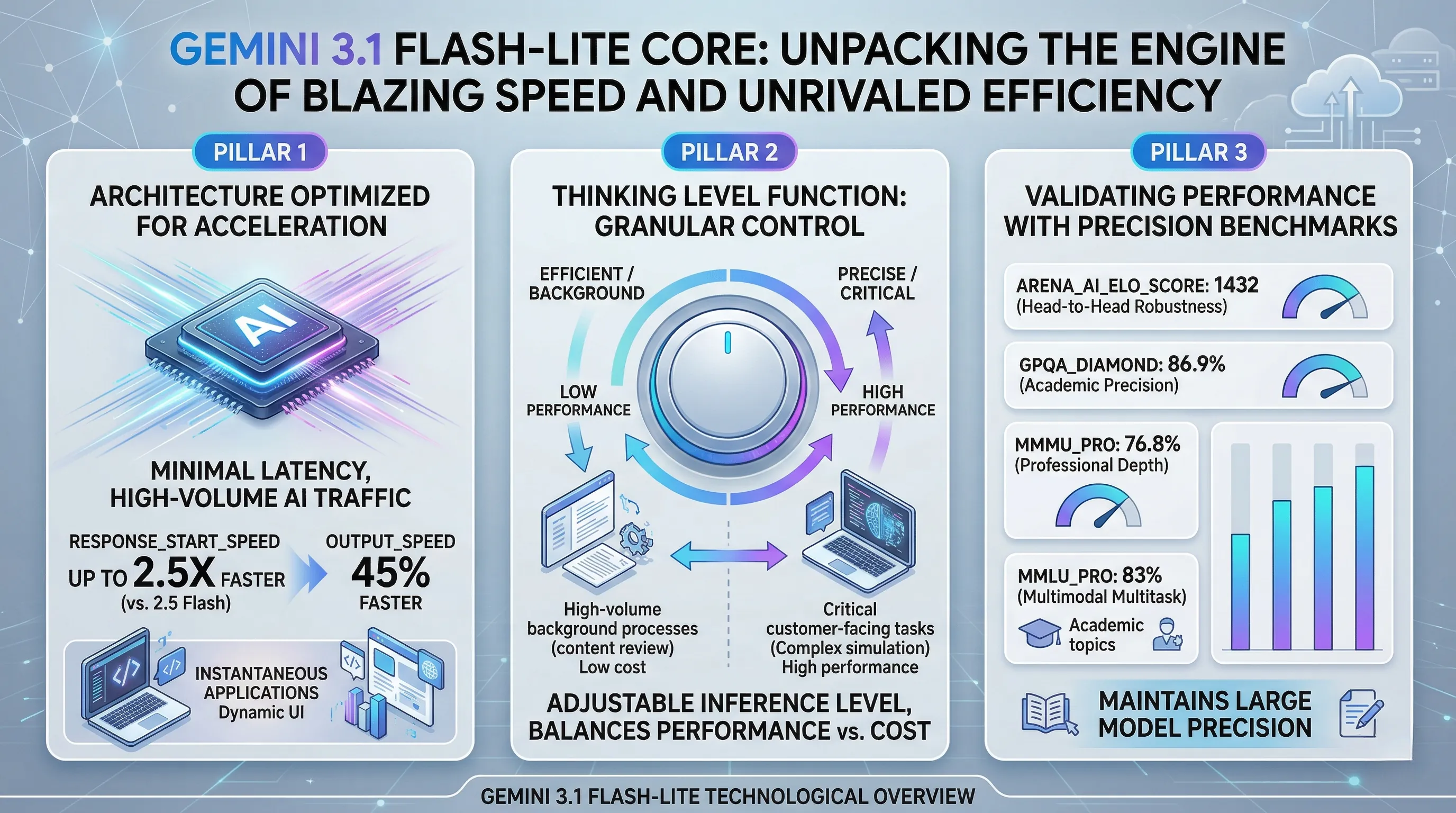
🔹 An Architecture Optimized for Acceleration
Gemini 3.1 Flash-Lite is engineered from the ground up for cost-sensitive, high-volume AI traffic and use cases demanding minimal latency.
Official performance metrics indicate a significant leap in responsiveness, with a Response_Start_Speed up to 2.5 times faster than its predecessor, 2.5 Flash.
Furthermore, the model's Output_Speed is 45% faster, enabling quicker generation of longer-form content.
A core innovation is the introduction of a 'Thinking Level function', an adjustable inference level that grants developers granular control over the balance between performance and cost.
🔹 Powering the Next Wave of Real-Time Services
This raw speed translates directly into the viability of building truly instantaneous AI-powered applications.
The combination of high throughput and low latency makes Flash-Lite suitable for constructing real-time services that previously faced prohibitive operational costs or performance bottlenecks.
Developers can now feasibly deploy large-scale tasks like on-the-fly content review, dynamic UI generation, and complex simulation design without compromising user experience.
The 'Thinking Level' feature acts as a strategic lever, allowing an enterprise to dial up performance for critical, customer-facing tasks while reducing cost for high-volume, less-complex background processes.
🔹 Validating Performance with Precision Benchmarks
Flash-Lite’s efficiency does not come at the expense of cognitive capability, a balance validated by strong benchmark performance.
The model achieves an impressive Arena_ai_Elo_Score of 1432, indicating robust overall performance in head-to-head comparisons.
It demonstrates high precision on complex academic and professional benchmarks, scoring 86.9% on GPQA_Diamond, 76.8% on MMMU_Pro, and 83% on MMLU_Pro.
These results substantiate the claim that Flash-Lite successfully maintAins large model precision, establishing it as the most cost-efficient Gemini model for developers who need to deliver both speed and quality at scale.
2. Shaking the AI Landscape: How Gemini 3.1 Flash-Lite Redefines the Performance-Price War
🔹 The New Benchmark for Budget AI
Gemini 3.1 Flash-Lite enters the market not just as an iteration, but as a strategic disruption aimed squarely at the cost-performance balance. It establishes its dominance over its predecessor, 2.5 Flash, by delivering superior performance and speed while being priced at just 70% of the cost.
More significantly, it challenges the top-tier market leaders head-on, with an input token price that is a staggering 1/10th that of the competing GPT-5.4 model.
This cost aggression is backed by formidable benchmark results, where Flash-Lite reportedly outperforms equivalent models, securing wins in 6 out of 11 direct comparisons against GPT-5.4.
🔹 From Theoretical Speed to Real-World Throughput
These metrics translate into a powerful competitive advantage for developers and enterprises building for scale.
The model's ultra-low input cost ($0.25 per 1M tokens) fundamentally changes the economics of high-volume workloads, making applications like large-scale translation, real-time content review, and simulation design more financially viable than ever.
This "cost-effective AI" approach is amplified by its speed, with a response start time up to 2.5x faster and output speeds 45% faster than existing models.
For developers, this means the ability to construct highly responsive, real-time services with high throughput and low latency, moving from a theoretical possibility to a practical reality without incurring prohibitive operational costs.
The inclusion of a 'Thinking Level' function further empowers developers to fine-tune the balance between performance and expenditure on a granular level.
🔹 The Community's Bottom Line: A Caveat on Cost
The developer community's reaction has been largely centered on the model's "crazy" speed and the exceptional value proposition of its input pricing.
However, a point of analytical friction has emerged regarding the output token cost, which at $1.50 per 1M tokens, is viewed by some users as a potential offset to the savings.
The central concern is whether the impressive benchmark victories were achieved using higher 'Thinking Level' settings, which could necessitate more verbose, and therefore more expensive, outputs.
While Flash-Lite is undeniably the most cost-efficient model in the Gemini family, its ultimate financial impact will depend heavily on the output token demands of specific, real-world use cases.

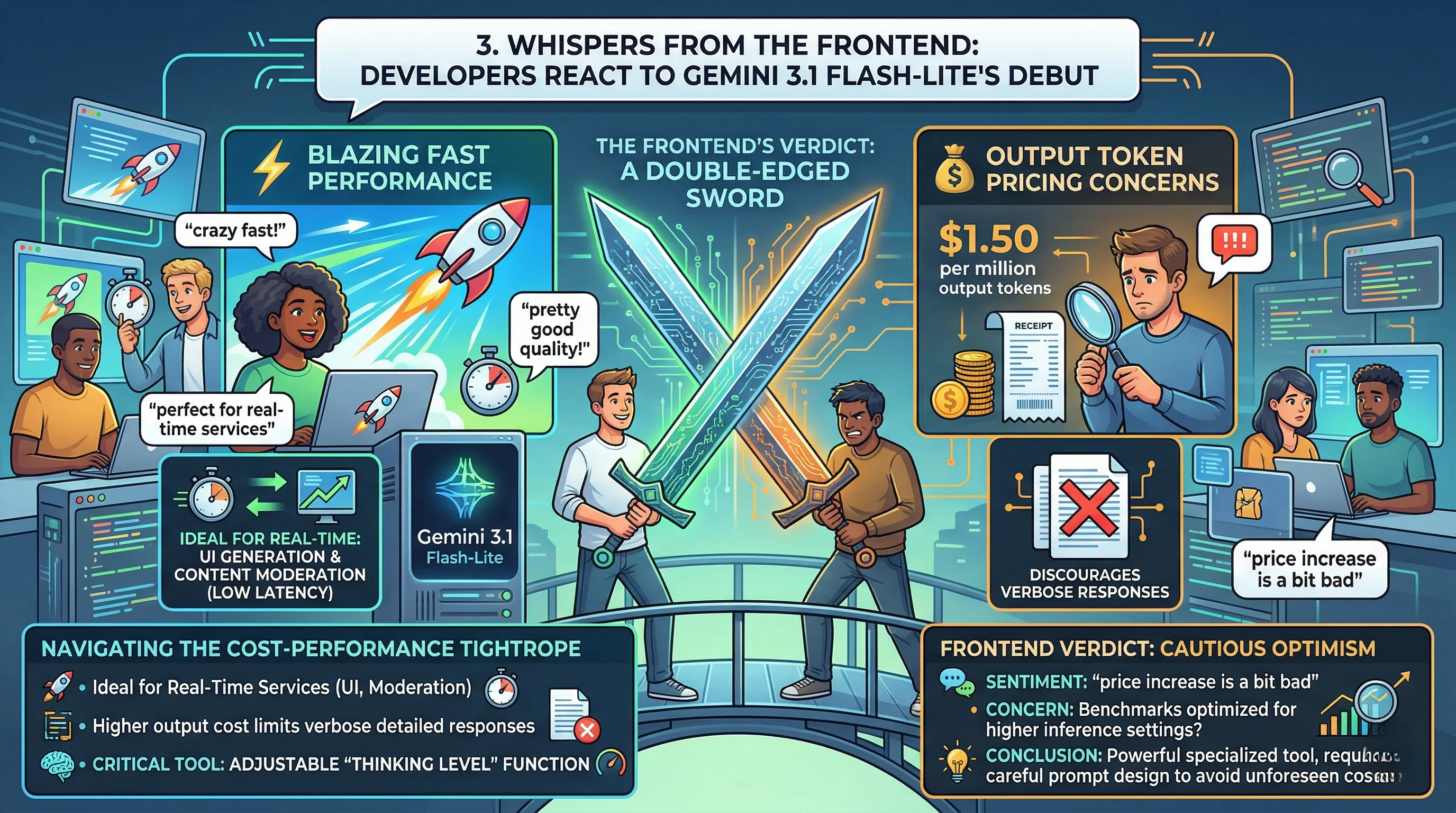
3. Whispers from the Frontend: Developers React to Gemini 3.1 Flash-Lite's Debut
🔹 Blazing Fast, But At What Output Cost?
Initial reactions from the developer community highlight a significant duality in Gemini 3.1 Flash-Lite's reception.
On one hand, user sentiment overwhelmingly describes the model's performance as 'crazy' fast, with the quality of its responses being lauded as 'pretty good' for its tier.
On the other hand, this enthusiasm is tempered by a pointed critique of its pricing structure, specifically the $1.50 per million output tokens.
🔹 Navigating the Cost-Performance Tightrope
This pricing model creates a new strategic challenge for developers building cost-sensitive, high-volume applications.
The model's blistering speed makes it an ideal candidate for real-time services like UI generation or content moderation, where low latency is non-negotiable.
However, the higher output cost could discourage use cases that require verbose, detailed responses, forcing teams to carefully architect prompts that elicit concise answers to manage operational spend.
This puts a spotlight on features like the adjustable 'Thinking Level' function, which becomes a critical lever for balancing the raw performance potential against a project's budget.
🔹 The Frontend's Verdict: A Double-Edged Sword
The consensus forming is one of cautious optimism, with developers viewing Flash-Lite as a powerful but specialized tool.
While the speed is a clear win, the sentiment that the 'price increase is a bit bad' suggests a friction point for adoption, especially when compared to previous models or competitor pricing.
Some users have voiced concerns that the impressive benchmark scores might have been achieved using higher inference settings, which in a real-world scenario would generate more output tokens and amplify the impact of the contested $1.50 price point.
Ultimately, the community sees a model with immense potential for specific, latency-critical tasks, but one that requires careful implementation to avoid unforeseen costs.
4. The Fine Print: Navigating Gemini 3.1 Flash-Lite's Perceived Pricing Hurdles
🔹 The Asymmetrical Cost Structure
While marketed as the most cost-efficient Gemini model, an analysis of Flash-Lite's pricing reveals a significant disparity between input and output costs.
The model features an aggressive input price of just $0.25 per one million tokens, positioning it as an exceptionally economical choice for processing large volumes of data.
However, the output cost stands at $1.50 per one million tokens, a six-fold increase over the input rate that has become a focal point of discussion for developers evaluating the total cost of ownership.
🔹 The Real-World Cost of Performance
This pricing model introduces a critical variable for developers: the nature of their workload.
For applications that are input-heavy but require concise outputs, such as large-scale translation or content review, Flash-Lite presents a clear financial advantage.
Conversely, concern has been raised within the community regarding workloads that necessitate verbose, detailed generation, as the higher output cost could quickly erode the initial savings.
This has led to pointed questions about the conditions under which the model's impressive benchmarks were achieved, with speculation that top performance might require settings that generate more output tokens, thereby driving up operational costs.
🔹 User Sentiment: A Calculated Compromise
Developer feedback has been swift to identify this potential hurdle, with prevailing sentiment noting that the perceived "price increase is a bit bad," likely in reference to the output cost relative to expectations or previous models.
The community largely views the $1.50 output fee as a calculated trade-off that must be actively managed.
While the model's speed and low-cost inputs are lauded, the consensus is that its ultimate cost-effectiveness is highly dependent on the use case, demanding careful architectural planning to avoid unexpectedly high costs on output-heavy tasks.

5. Beyond the Preview: Gemini 3.1 Flash-Lite's Trajectory Towards Enterprise AI Dominance
🔹 The Strategic Rollout: A Beachhead in Enterprise Infrastructure
The current deployment of Gemini 3.1 Flash-Lite is not a broad consumer launch; it is a highly targeted strategic maneuver.
By making the model available in preview exclusively through the Gemini API for developers and Vertex AI for enterprises, Google is signaling its primary objective.
The model is explicitly engineered for cost-sensitive, high-volume workloads and short-latency use cases, directly addressing the core operational challenges of large-scale AI integration.
This positions Flash-Lite less as a general-purpose model and more as a foundational utility, akin to a specialized cloud computing instance, designed to be embedded deep within corporate infrastructure.
🔹 From Latency Bottleneck to Real-Time Service Construction
For an enterprise, the spec sheet translates directly into new operational capabilities.
The model's optimization for high throughput and low latency means businesses can move beyond batch-processing AI tasks and build genuinely real-time services.
This unlocks applications previously hampered by lag, such as on-the-fly UI generation that adapts to user input instantly or content review systems that can filter vast streams of data without creating a backlog.
For developers tasked with building these systems, the combination of extreme speed and a remarkably low input token price ($0.25 per 1M tokens) removes significant financial and performance barriers, making it feasible to deploy AI for tasks like large-scale translation or complex simulation design across an entire organization.
🔹 A Calculated Play with a Pricing Question Mark
Community and developer analysis points to Flash-Lite as a deliberately disruptive force in the market, with its input token price pegged at a fraction of key competitors.
The model is not just an incremental update; it's a strategic tool designed to capture high-volume enterprise traffic by making the cost of large-scale data ingestion almost negligible.
However, this aggressive input pricing is counterbalanced by a higher output token cost ($1.50 per 1M tokens), a detail that has not gone unnoticed by developers.
The prevailing expert take is that Google is incentivizing the adoption of Flash-Lite for data-heavy, analysis-focused tasks, betting that the overwhelming speed and initial cost savings will anchor it as the go-to model for a new generation of enterprise-grade, real-time AI applications, even with the higher cost for generating verbose responses.

6. 💡 Tech Talk: Making Sense of the Jargon
- Thinking Level Function: Imagine you're commissioning a piece of art; sometimes you need a quick sketch, other times a meticulously detailed masterpiece.
This function is like telling the AI how "deeply" to "think" or how complex and detailed its response needs to be for a given task.
It allows you to adjust the inference level to either save on "paint" (cost) for simple requests or spend more for intricate, high-quality results. - High Throughput, Low Latency: Think of a world-class postal service that handles mail.
High throughput means they can process and deliver millions of letters (requests) every single day without getting overwhelmed.
Low latency means that once you drop your letter in the mailbox, it reaches its destination incredibly quickly.
Gemini 3.1 Flash-Lite is designed to process an enormous volume of AI requests (high throughput) while ensuring each individual request gets a response almost instantly (low latency).
📚 Related Posts
Google Gemini 3.1 Flash Live: Real-time Voice AI Revolution
🚀 Key TakeawaysGemini 3.1 Flash Live is Google's highest-quality audio and voice model, engineered for real-time, natural dialogue and exceptionally reliable voice-first AI interactions.It features unprecedented tonal understanding, dynamically adjustin
tech.dragon-story.com
Google's February AI Blitz: New Gemini Models, Creative Tools, and a Global Vision
🚀 Key TakeawaysGoogle's February AI Blitz unveiled a significant push for more capable and specialized AI, focusing on empowering both advanced problem-solving and creative expression across diverse applications.This included the release of Gemini 3.1 P
tech.dragon-story.com
Gemini's AI Music Feature: The Ultimate Guide to Lyria 3
🚀 Key TakeawaysGemini's new AI music feature, powered by Lyria 3, allows users to effortlessly create custom 30-second music tracks from text descriptions or even images, generating instrumental audio or tracks with lyrics and unique cover art.Lyria 3,
tech.dragon-story.com



