🚀 Key Takeaways
- Gemma 4 redefines open AI, offering frontier-level performance and unparalleled efficiency across diverse model sizes and hardware, effectively closing the gap with proprietary models and making advanced AI accessible from edge devices to enterprise servers.
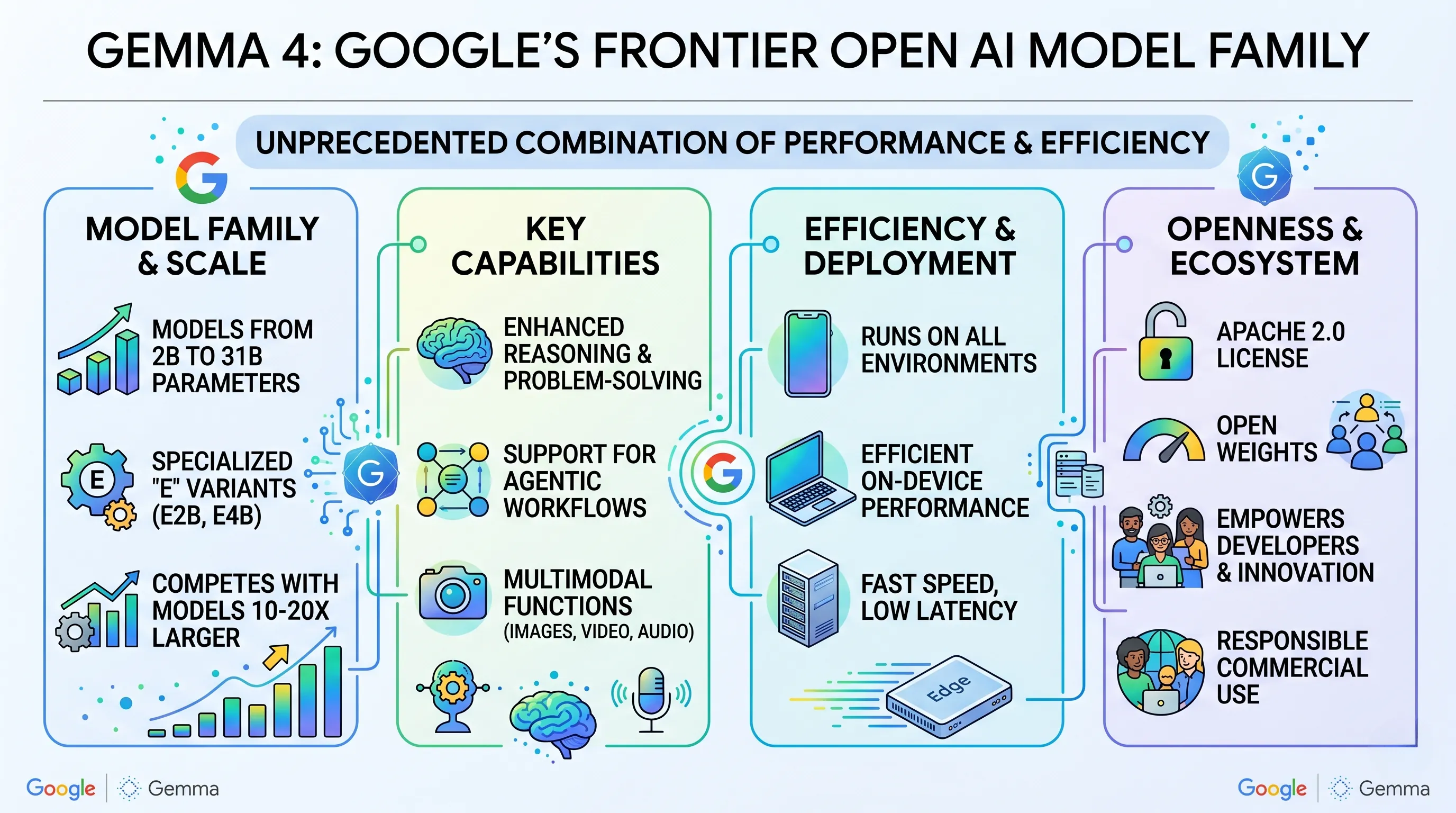
Gemma 4, Google's latest iteration in its open AI model series, has made its debut, marking a significant advancement in the realm of artificial intelligence.
This release is designed to deliver an unprecedented combination of frontier-level performance and exceptional efficiency across a diverse range of model sizes.
With Gemma 4, Google aims to push the boundaries of what open models can achieve, empowering developers with advanced capabilities previously associated only with much larger, closed systems.
The Gemma 4 series includes models ranging from 2B to 31B parameters, featuring specialized 'E' variants (E2B, E4B) that demonstrate remarkable performance relative to their effective size.
Key features include enhanced reasoning ability, support for agentic workflows, and multimodal functions capable of processing images, video, and audio.
Critically, these models are engineered to run efficiently across virtually all environments, from smartphones and laptops to powerful servers and edge devices, maintaining fast speed and low latency on-device.
Gemma 4 is released with an Apache 2.0 license and open weights, encouraging broad developer participation and responsible commercial use, thereby expanding the open AI ecosystem.
Benchmarks highlight its ability to compete with models 10-20 times its size, effectively closing the performance gap between open and proprietary AI for many practical applications.
This strategic move provides developers with powerful, resource-efficient tools to implement high-performance AI in their own projects, making advanced AI more accessible and adaptable than ever before.
1. Gemma 4's Unmatched Performance: A Deep Dive into its Benchmarks and Architecture
This section directly validates the main topic, "GEMMA 4, Capturing Both Performance and Efficiency," by examining the concrete data and design choices behind its success.
We will explore how Google has engineered a family of models that not only competes at the highest level of AI leaderboards but does so with an architectural elegance that maximizes performance relative to its size, delivering a new standard for what is possible in the open AI ecosystem.
A Spectrum of Power: The Gemma 4 Model Family
Gemma 4 is not a monolithic entity; it is a strategically designed family of models, available in 2B, 4B, 26B, and 31B parameter sizes.
This range ensures that developers can select the perfect balance of power and resource consumption for their specific needs, from on-device applications to large-scale server deployments.
A key innovation lies within the smaller models, designated as 'E' variants like E2B and E4B.
The 'E' stands for 'effective parameters,' a concept that underscores Gemma's focus on efficiency.
These models are engineered to punch far above their weight class, delivering performance comparable to much larger models without the associated computational overhead.
This approach is a direct manifestation of achieving both peak performance and remarkable efficiency, allowing sophisticated AI to run in more constrained environments.
Redefining the Leaderboards: Benchmark Dominance
Gemma 4's performance is not just theoretical; it's proven through rigorous, competitive benchmarking.
The results reveal a clear pattern of superior capability, often in defiance of traditional "bigger is better" assumptions.
- Multi-Turn Mastery:
In conversational AI, maintaining context and coherence over multiple turns is the ultimate test.
Here, the smaller models shine brilliantly.
The E2B (2B model) achieves an impressive 70% score on multi-turn benchmarks, a result so strong it even surpasses some of its larger siblings.
This is an incredible feat, offering developers a lightweight model that excels at complex dialogue.
The E4B model raises the bar even higher, scoring a formidable 83.6% on multi-turn tasks, solidifying its position as a premier choice for sophisticated conversational agents. - The Efficiency Champion (26B A4B):
The 26B model is a masterpiece of efficient design.
Despite its 26 billion total parameters, this model ingeniously activates only 3.8B parameters per forward pass.
This is the experiential equivalent of having a V12 engine that only uses three cylinders for most driving, saving immense fuel while keeping the full power on immediate reserve.
This efficiency does not compromise its power; the 26B A4B model ranks an astounding 6th on the Arena AI text leaderboard with a score of 1,441, placing it among the world's elite text generation models. - Global Heavyweight (31B):
The largest model in the family, the 31B variant, lives up to its flagship status by ranking high in global AI performance evaluations, proving that Gemma 4 can compete and win against both open and closed models at the highest echelons of AI capability.
The Architectural Advantage and Real-World Speed
Underpinning this performance is a flexible and intelligent design philosophy.
Gemma 4 is built on three distinct architectures, each tailored for specific hardware requirements.
This allows the models to be optimized for the environment they run in, whether it's a smartphone, a developer's laptop, or a cloud server, ensuring maximum efficiency and speed.
However, raw potential is only part of the story; real-world deployment speed is critical.
For the powerful 31B model, performance varies significantly based on the inference provider.
This highlights a crucial consideration for developers: the underlying infrastructure is as important as the model itself.
For instance, when benchmarked for reasoning tasks, the 31B model running on FriendliAI achieved an output speed of 71.3 tokens/second.
This is a staggering 5.7 times faster than its performance on Together.ai, demonstrating that choosing the right deployment partner can unlock dramatic gains in speed and user experience, directly impacting the model's practical efficiency.

2. Bridging Power and Portability: Gemma 4's Innovative Efficiency Features
The central thesis of Gemma 4, directly aligning with the overarching theme of capturing both performance and efficiency, is its refusal to treat power and portability as a zero-sum game.
Instead of simply scaling up parameters to achieve intelligence, Google has engineered Gemma 4 from the ground up with an innovative philosophy that maximizes "performance relative to parameters," effectively delivering heavyweight intelligence in a lightweight package.
This design ethos is not a mere marketing claim but is evident in a suite of specific, interconnected features that allow Gemma 4 to redefine what is possible for open models, whether running in a massive data center or on a local smartphone.
Maximizing Intelligence per Parameter
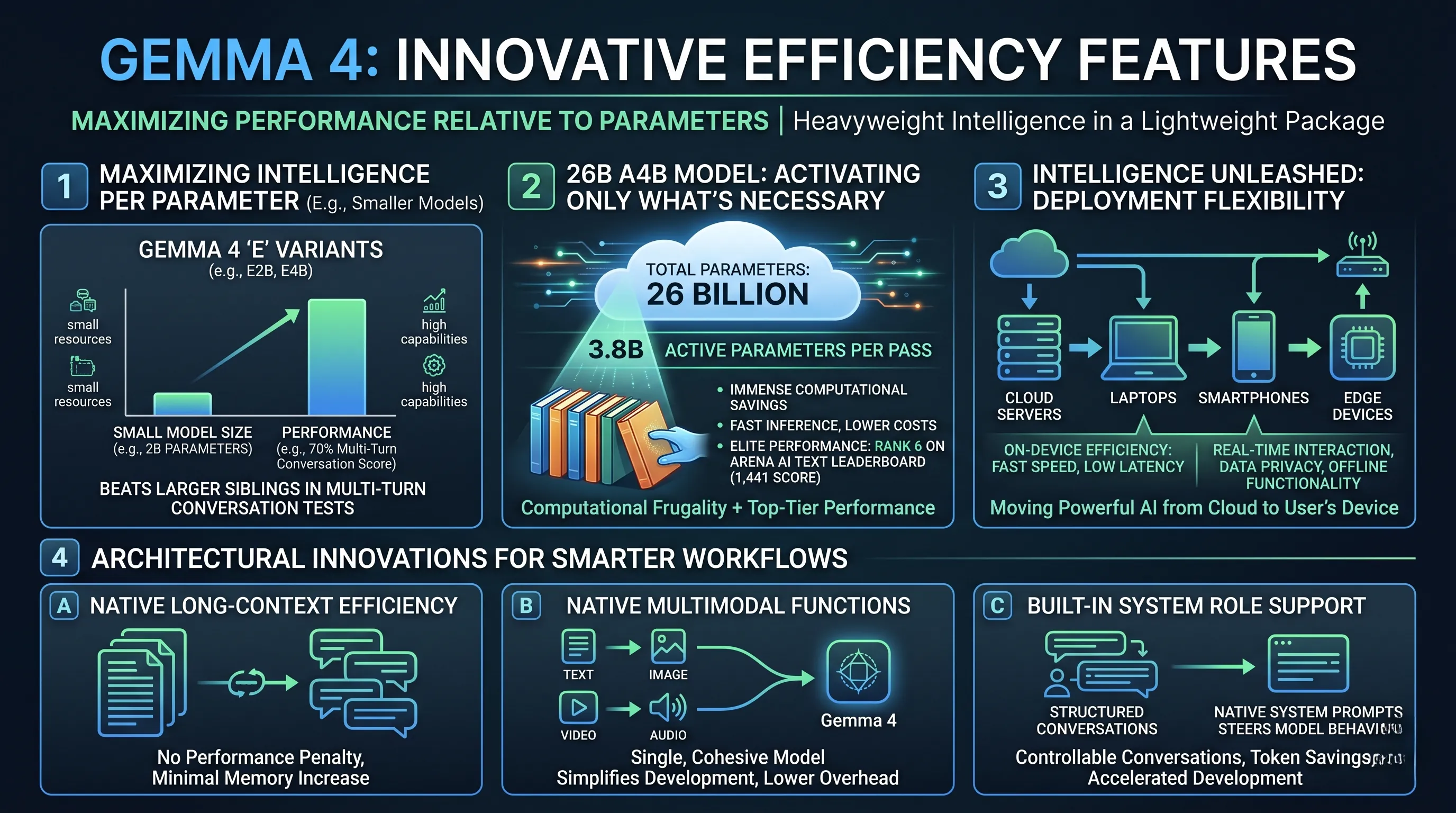
The most direct evidence of Gemma 4's efficiency-first approach lies in its smaller models, specifically the 'E' variants like E2B and E4B.
The 'E' designation stands for 'effective parameters,' a concept that signals these models are architected to punch far above their weight class.
This is not a theoretical benefit; performance benchmarks reveal a stunning reality where the Gemma 4 E2B model, with only 2 billion parameters, managed to beat its larger siblings in multi-turn conversation tests with a 70% score.
This achievement demonstrates a core principle of Gemma 4: raw parameter count is a brute-force metric, whereas architectural intelligence and training optimization can yield superior results with a fraction of the computational cost.
For developers, this translates into a powerful experiential value: the ability to deploy AI with sophisticated reasoning capabilities without needing the massive hardware resources typically associated with such performance.
It embodies the pro of being a "high performance comparable to models 10-20 times larger," directly empowering developers to build next-generation applications with significantly fewer resources.
The 26B A4B Model: Activating Only What's Necessary
Perhaps the most groundbreaking feature showcasing Gemma 4's efficiency is found in its 26B A4B model.
While its total parameter count is 26 billion, the model employs a sophisticated architecture where it activates only 3.8B parameters per forward pass.
A "forward pass" is the fundamental process of the model generating a response; by activating only a fraction of its total knowledge base for any given query, Gemma 4 achieves an extraordinary balance of speed and power.
This is akin to having a vast library where, instead of reading every book for every question, a master librarian instantly pulls only the most relevant volumes.
The result is immense computational savings, leading to faster inference speeds and lower operational costs.
This efficiency does not come at the cost of performance. On the contrary, this very model ranks an astonishing 6th on the Arena AI text leaderboard with a score of 1,441, placing it among the world's elite text models.
This single feature perfectly encapsulates the article's main topic: it achieves top-tier performance (performance) while operating with a level of computational frugality (efficiency) that was previously unimaginable for a model of its caliber.
Intelligence Unleashed: From Cloud Servers to Edge Devices
Gemma 4's architectural efficiency is not just an academic exercise; it directly enables unprecedented deployment flexibility.
The model family is explicitly designed to run in a vast array of environments, from powerful cloud servers to smartphones, laptops, and other mobile and edge devices.
This portability is a direct consequence of the features mentioned above—the highly optimized smaller models (2B, 4B) and the low-activation architecture of the larger ones.
Crucially, Gemma 4 is engineered to maintain fast speed and low latency in on-device environments.
This is a game-changer, moving powerful AI from the exclusive domain of the cloud to the immediate, responsive context of a user's own device.
Applications requiring real-time interaction, data privacy, or offline functionality can now leverage frontier-level AI without the lag of a network roundtrip.
Architectural Innovations for Smarter Workflows
Beyond parameter optimization, Gemma 4 incorporates several native features that enhance efficiency at the workflow and development level.
First, it boasts native long-context efficiency from its model architecture.
Many models can handle long inputs but suffer from a drastic slowdown or a massive increase in memory consumption. Gemma 4's design anticipates and mitigates this, making it inherently efficient for tasks like summarizing lengthy documents or maintaining coherent, extended conversations without a performance penalty.
Second, its multimodal functions—the ability to process not just text but also images, video, and audio—represent a profound workflow efficiency.
Developers no longer need to stitch together multiple, disparate models for different data types. A single, cohesive Gemma 4 instance can handle complex, mixed-media tasks, simplifying development, reducing infrastructure complexity, and lowering overhead.
Finally, its built-in support for system roles (native system prompt support) enables more structured and controllable conversations.
This seemingly small feature provides immense efficiency gains for developers. It allows them to steer the model's behavior reliably and concisely, reducing the need for lengthy and complex prompt engineering, which in turn saves tokens, minimizes errors, and accelerates development cycles.
Each of these features demonstrates a commitment to a holistic view of efficiency, where performance is balanced not just with computational cost, but also with developer productivity and application versatility.
3. Empowering Developers: Gemma 4's Impact on the Open AI Ecosystem and Commercial Use
Gemma 4's core achievement, as highlighted by the main topic "GEMMA 4, Capturing Both Performance and Efficiency," is not just a technical benchmark; it's a fundamental shift that directly empowers the global developer community.
This section explores how Google's strategic combination of top-tier performance, resource efficiency, and an open, commercially-friendly framework is setting a new standard for the open AI ecosystem.
Breaking Down Barriers: High Performance with Fewer Resources
For developers, the single greatest barrier to entry in advanced AI has always been the immense computational cost.
Gemma 4 directly dismantles this barrier by delivering performance that was previously the exclusive domain of models 10 to 20 times its size.
This isn't just an incremental improvement; it's a paradigm shift in resource management, embodying the article's central theme of achieving both "performance" and "efficiency".
The most striking example of this is the 26B A4B model, a powerhouse that astonishingly activates only 3.8B parameters per forward pass.
The experiential value for a developer is profound: they gain access to the nuanced reasoning and knowledge of a 26-billion-parameter model while only paying the computational and memory toll of a sub-4-billion-parameter model during inference.
This dramatically lowers the hardware requirements, making it feasible to run sophisticated AI on local machines or more affordable cloud instances.
The smaller "E" variants, which stand for "effective parameters," further democratize access to power.
The E2B model, with just 2 billion parameters, impressively beat its larger siblings in multi-turn conversation benchmarks with a 70% score, while the E4B model achieved a remarkable 83.6%.
This demonstrates that developers do not need to default to the largest possible model for high-quality, interactive applications.
By providing a spectrum of highly optimized models (2B, 4B, 26B, 31B), Google enables developers to select the perfect tool for the job, ensuring they can implement high-performance AI without overprovisioning resources.
Unleashing Creativity: Expanded Application Range and Flexibility
Gemma 4's efficiency directly translates into unprecedented flexibility, expanding the canvas for what developers can create.
The ability to run effectively in diverse environments—from smartphones and laptops to servers, mobile, and edge devices—liberates AI from the datacenter.
Developers can now realistically build applications with fast, low-latency AI that operates directly on a user's device, ensuring privacy and responsiveness without a constant need for a network connection.
This capability is further enhanced by Google's provision of three distinct architectures, each tailored for specific hardware requirements, signaling a deep understanding of developers' deployment challenges.
The creative potential is magnified by Gemma 4's native multimodal functions.
The ability to process not just text, but also images, video, and audio, opens up a vast new territory for innovation.
A developer can now build an application that analyzes a video, generates a descriptive script, and translates it, all within a single, cohesive open-source framework.
Furthermore, features like built-in support for a system role (native system prompts) provide developers with more structured and controllable conversations, a critical feature for building reliable and predictable commercial-grade agents and applications.
This combination of environmental flexibility and functional range is a direct result of achieving the performance and efficiency promised by the article's title.
A New Era of Open Innovation: Commercial Use and Open Weights
Perhaps the most significant contribution of Gemma 4 to the developer ecosystem is its licensing and distribution model.
Released under the permissive Apache 2.0 license, Gemma 4 is free for responsible commercial use.
This is a monumental decision by Google that removes legal and financial friction, empowering startups, independent developers, and established enterprises to build and monetize solutions without exorbitant licensing fees.
It is a clear signal of Google's intent to expand the entire open AI ecosystem and encourage broad developer participation.
Coupled with the open license is the provision of open weights.
This is the equivalent of being given not just the car, but the complete factory schematics.
It allows developers to go beyond simple API calls and truly tune and deploy the models in their own projects.
They can fine-tune Gemma 4 on proprietary datasets to create highly specialized experts for any domain, from legal analysis to medical transcription.
This deep level of access and control, combined with the model's inherent performance-to-cost efficiency, creates a fertile ground for innovation that proprietary, black-box models simply cannot match.
Closing the Chasm: Bridging the Gap Between Open and Closed Models
For years, a choice had to be made: the customizability of open models or the raw power of closed, proprietary models.
Gemma 4 effectively argues that this choice is becoming obsolete.
The user reaction that the gap between open and closed models is now "gone' for many use cases" is not hyperbole; it is backed by objective data.
The 26B A4B model, for instance, ranks an incredible 6th on the Arena AI text leaderboard with a score of 1,441, while the 31B model consistently ranks high in global AI performance evaluations.
These are not just "good for an open model" scores; this is top-tier, frontier-level performance, validating Gemma 4's claim as one of the "most intelligent open models to date."
By delivering this elite level of performance within an efficient, open, and commercially viable package, Google has provided the developer community with the tools to build applications that are not only innovative but also truly competitive.
Gemma 4 successfully delivers on the promise of "Capturing Both Performance and Efficiency," empowering developers to build the future of AI without compromise.

📚 Related Posts
Google Veo 3.1 Lite: $0.05 AI Video Disrupts Market, Accelerating Mass Adoption & High-Volume Creation
🚀 Key TakeawaysGoogle's Veo 3.1 Lite redefines AI video generation pricing at an unprecedented $0.05 per video, making it the most cost-effective model available.It significantly lowers the barrier to entry for developers, enabling the creation of high-
tech.dragon-story.com
Microsoft Unleashes Next-Gen MAI Models: MAI-Transcribe, MAI-Voice, MAI-Image-2 Redefine AI for Developers
🚀 Key TakeawaysMicrosoft has launched three next-generation MAI models—MAI-Transcribe-1, MAI-Voice-1, and MAI-Image-2—offering groundbreaking advancements in speech recognition, voice generation, and image creation with unparalleled accuracy, speed,
tech.dragon-story.com
Microsoft's MAI-Transcribe-1: Revolutionizing Speech Recognition with 3.9% WER, 2.5x Speed, and Unmatched Enterprise Value
🚀 Key TakeawaysMAI-Transcribe-1 by Microsoft is redefining speech recognition standards, offering unprecedented accuracy with an average 3.9% Word Error Rate across 25 languages, superior speed (2.5 times faster), and significant cost savings, making it
tech.dragon-story.com



