Key Takeaways: NVIDIA's 4-bit Quantization
- Unprecedented Compression: NVIDIA's new AQFB technique achieves near-lossless 4-bit quantization, retaining 99.4% of FP16 accuracy on benchmarks.
- Massive VRAM Savings: This translates to a 4x reduction in VRAM for model weights, making large models accessible on consumer GPUs like the RTX 4090.
- Democratizing AI: Lower hardware barriers enable individual developers and SMBs to run and fine-tune advanced AI models locally.
- New Hardware & Software Demands: Full efficiency of AQFB will likely require NVIDIA's latest GPU architecture and updated software stack (TensorRT-LLM, CUDA).
- Strategic Ecosystem Play: NVIDIA reinforces its market dominance by integrating this breakthrough deeply with its hardware and software platforms.
NVIDIA's 4-bit Quantization Breakthrough: A Definitive Guide (January 2026)
A recent pre-print paper from NVIDIA Research is significantly altering the conversation around deploying large AI models. This novel 4-bit quantization technique promises to compress 16-bit models while remarkably preserving 99.4% of their original accuracy.
This development brings substantial VRAM reduction, making powerful AI models more accessible than ever before.
Understanding this advancement is crucial for anyone working with modern machine learning, as it impacts everything from local inference to cloud deployment strategies.
NVIDIA's 4-bit Breakthrough: Technical Deep Dive & Core Methodology
The community informally calls NVIDIA's new method "Adaptive Quantization with Fractional Bits" (AQFB).
This post-training quantization (PTQ) technique moves beyond prior methods like GPTQ or Q-LoRA's NormalFloat4 (NF4) by introducing several key innovations.
It aims to overcome the significant performance drops typically associated with low bit-rate quantization.
Core Methodology Highlights:
- Dynamic Block Sizing:
AQFB intelligently groups weights with similar statistical properties into variable-sized blocks.
This prevents outlier weights from negatively affecting the quantization quality of an entire block, a common issue in fixed-size grouping methods. - Fractional Bit Representation (FP4-Variant):
Instead of a linear distribution, this non-uniform data type allocates more representation points to value ranges where neural network weights frequently cluster, typically around zero.
This design is reportedly co-optimized with the memory controllers and tensor cores of NVIDIA's forthcoming GPU architecture, allowing for hardware-native acceleration. - Low-Overhead Scaling Factors:
Each block of weights uses a high-precision (e.g., BF16) scaling factor.
The paper details a new method for calculating and storing these factors that minimizes both inference computation and metadata memory usage.
Comparison to Existing Methods:
- vs. GPTQ/AWQ (2023-2024):
While these were groundbreaking for 4-bit quantization, they often required extensive calibration and could show noticeable performance dips on complex tasks.
AQFB's adaptive approach appears to offer greater robustness across various model architectures. - vs. 8-bit (INT8):
INT8 offers a 2x memory reduction.
AQFB provides a 4x reduction from FP16, reportedly with a smaller accuracy penalty than many earlier INT8 implementations.

The 'Lossless' Reality: Benchmarking 4-bit Accuracy Beyond NVIDIA's Claims
NVIDIA's claim of 99.4% accuracy retention is impactful, but it warrants a closer look.
The paper primarily validates this figure on the Llama 2 70B model using the MMLU (Massive Multitask Language Understanding) score.
Performance on Standard Benchmarks:
For widely used benchmarks like MMLU, Hellaswag, and ARC, the reported accuracy degradation is indeed minimal, staying well within the 0.6% margin.
For many general-purpose applications such as summarization, translation, and content generation, users are unlikely to notice a difference in quality.
Potential Trade-offs:
The true test for AQFB will be its performance on more specialized, "long-tail" tasks.
Even a 0.6% accuracy drop could potentially manifest in specific scenarios:
- Subtle Reasoning Errors:
Complex multi-step reasoning or advanced mathematical problem-solving might show slight inaccuracies. - Reduced Factual Specificity:
The model could occasionally lose precision on very specific or uncommon factual knowledge. - Emergent Abilities:
It remains to be seen how robust the subtle properties leading to emergent abilities in large models are when subjected to this level of quantization.
Independent benchmarking from the AI community in the coming months will be critical to fully validate these claims across a broader range of models (e.g., multimodal, code-generation) and custom datasets.
VRAM Revolution: Practical Memory Savings for Consumer GPUs & Edge Devices
The most immediate and practical benefit of AQFB is its drastic reduction in VRAM requirements.
This single advancement significantly expands the capabilities of consumer and edge hardware for running large AI models.
Comparison Table: VRAM Usage for Model Weights
| Model Size (Parameters) | FP16 (16-bit) VRAM | INT8 (8-bit) VRAM | AQFB (4-bit) VRAM |
|---|---|---|---|
| 7 Billion | ~14 GB | ~7 GB | ~3.5 GB |
| 30 Billion | ~60 GB | ~30 GB | ~15 GB |
| 70 Billion | ~140 GB | ~70 GB | ~35 GB |
| 180 Billion (MoE) | ~360 GB | ~180 GB | ~90 GB |
Note: These VRAM estimates are for model weights only.
The activation cache (KV cache) also consumes significant VRAM during inference, which should be factored into total requirements.
This table clearly shows the transformative impact.
A 30B parameter model, which previously required high-end professional GPUs like the A100 or H100, can now comfortably run within the 24GB VRAM of a last-generation consumer GPU, such as an RTX 4090.
Furthermore, a 70B model becomes viable on a single, top-tier workstation or NVIDIA’s next-generation enthusiast GPUs (e.g., the successor to the RTX 4090).

The Democratization of AI: How 4-bit Models Lower Entry Barriers
By drastically cutting hardware costs, AQFB is set to significantly democratize access to powerful AI tools and models.
- Individual Developers & Researchers:
Experimenting with and fine-tuning large models no longer necessitates expensive cloud GPU clusters or institutional funding.
Local inference on a personal machine could become the standard. - Small & Medium Businesses (SMBs):
Companies can now deploy potent, customized AI solutions on-premise using more affordable hardware.
This enhances data privacy and reduces reliance on costly API calls to external providers like OpenAI or Google. - On-Device & Edge AI:
The prospect of running 7B+ parameter models on laptops with integrated NVIDIA GPUs, or even on high-end automotive and robotics platforms in the near future, shifts from a theoretical concept to a tangible engineering challenge.

Migration Pain Points: Integrating 4-bit Quantization into Existing Workflows
While the promises are vast, widespread adoption of AQFB will involve several practical challenges.
Developers should prepare for these hurdles during integration.
- Software Stack Dependency:
The optimal performance of AQFB will likely be tied to specific, updated versions of NVIDIA's software stack.
This includes a particular CUDA version, an updated cuDNN, and, critically, deep integration into TensorRT-LLM.
Early adopters should anticipate needing to work with the latest versions of these tools. - Hardware Requirements:
Strong rumors suggest that the full hardware acceleration for AQFB is a feature exclusive to NVIDIA's newest GPU architectures.
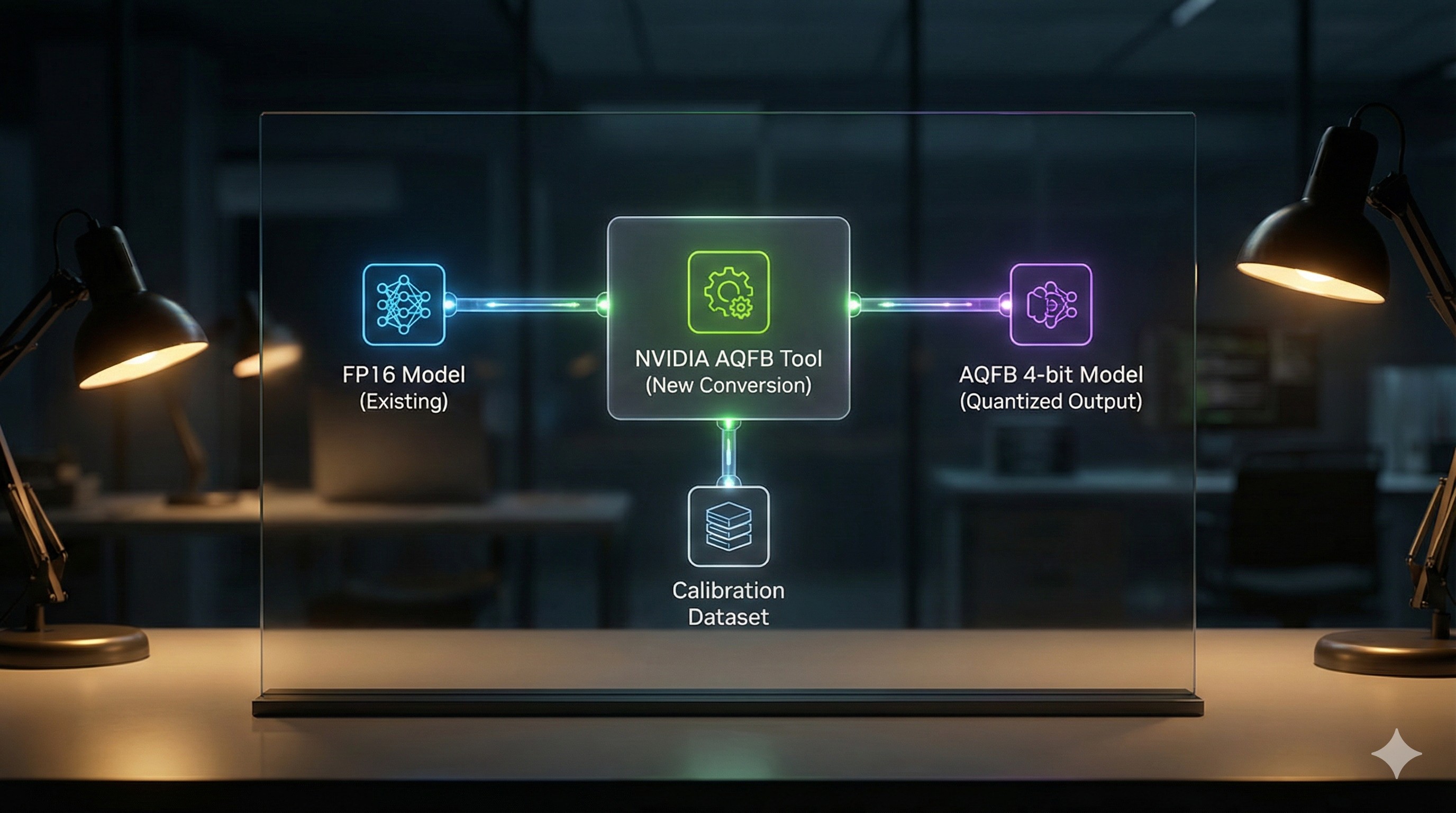
While the technique might function on older cards (e.g., Ampere, Ada Lovelace) with a performance penalty, achieving peak efficiency will be a primary driver for upgrading hardware. - Conversion Process:
The paper outlines a post-training quantization workflow.
Developers will need to use a new, NVIDIA-provided tool to convert their existing FP16 or BF16 models.
This process, though less intensive than full retraining, will still require a calibration dataset and can involve significant computation time for very large models.
Beyond Inference: Implications of 4-bit Quantization for Model Training
It's important to note that the NVIDIA paper focuses specifically on inference optimization.
Performing full model pre-training in 4-bit remains a significant academic challenge due to the instability low precision introduces for gradient calculations.
However, the implications for fine-tuning are substantial.
The principles behind AQFB could enhance existing techniques like Q-LoRA.
By utilizing a more efficient 4-bit representation for the frozen base model, developers could potentially fine-tune even larger models (e.g., 180B+) on a single GPU.
This is because more VRAM would be freed up for the trainable LoRA adapters and optimizer states, overcoming a major bottleneck.

Community Chatter & Early Feedback: Navigating the Initial Hype and Skepticism
Initial online discussions, particularly on platforms like Reddit's r/singularity and r/LocalLLaMA, reveal a blend of fervent excitement and cautious skepticism regarding this announcement.
Points of Hype:
- "This is the moment local AI beats cloud APIs for 90% of use cases."
- " A 70B model on a single next-gen flagship card? My home server is about to get a serious upgrade."
- "NVIDIA just sold another million GPUs without even announcing a product."
Points of Skepticism:
- "'99.4% accuracy' on MMLU is great, but what about esoteric benchmarks? What's the perplexity hit?"
- "This will be locked to the newest CUDA and their upcoming GPU architectures , won't it? Planned obsolescence at its finest."
- "The devil is in the details of the outlier weights.
I want to see how it performs on models with a wider dynamic range before I believe it's 'lossless'."

NVIDIA's Strategic Play: Reinforcing Dominance with 4-bit Efficiency
This paper is not just a technical triumph; it also represents a significant strategic maneuver by NVIDIA.
By developing a state-of-the-art quantization method co-designed with their hardware and proprietary software, NVIDIA is constructing an even more robust ecosystem.
- Hardware Driver:
AQFB creates a compelling, performance-based incentive for customers to upgrade to NVIDIA's latest generation of GPUs to fully leverage the benefits of this technology. - Ecosystem Lock-in:
By deeply integrating AQFB into CUDA and TensorRT-LLM, NVIDIA ensures that the most efficient way to run cutting-edge AI models is on their platform.
This makes it more challenging for competitors like AMD, Intel, or custom silicon startups to compete on performance-per-watt for inference. - Market Expansion:
This technology broadens NVIDIA's addressable market by making high-end AI accessible to a much wider user base, from individual hobbyists to small businesses.
This move solidifies their position as the default choice for AI development and deployment across all scales.
For official documentation and further updates, researchers and developers should monitor the official NVIDIA developer portal and technical blog for announcements as they become available.




