🚀 Key Takeaways
- OpenAI's new "Privacy Filter" is an open-weight and open-source AI model dedicated to detecting and masking Personally Identifiable Information (PII) across diverse text formats, offering a robust solution for data privacy.
- The model utilizes sophisticated context understanding, not just pattern matching, to achieve high accuracy (97% F1 score) in unstructured text and long documents, capable of nuanced judgments like retaining public figure names.
- Designed for high security, it can run locally on internal systems, ensuring sensitive data is processed without external server transmission, making it ideal for industries like finance, medical, and legal.
- Its release signifies an expansion of the generative AI competition into the realm of privacy protection infrastructure, aiming to empower developers to build secure systems from early stages.
OpenAI has unveiled its "Privacy Filter," an innovative AI model specifically engineered to address the critical need for data privacy by detecting and masking Personally Identifiable Information (PII) across various text-based data.
This advanced solution is designed to handle everything from documents and chats to log data, automatically identifying sensitive details such as names, phone numbers, emails, addresses, account numbers, and even API keys.
Its strength lies in its ability to understand context rather than relying solely on simple pattern searching, enabling sophisticated judgments like distinguishing between public figures and ordinary personal names.
The "Privacy Filter" stands out for its technical prowess and operational flexibility.
As a 1.5-billion-parameter mixture-of-experts model, it is both open-weight and open-source, released under an Apache 2.0 license, making it accessible on Hugging Face and GitHub.
Crucially, it boasts an impressive F1 score in the 97% range on the PII-Masking-300k benchmark, demonstrating high accuracy even with long inputs up to 128,000 tokens.
This capability, combined with its small and lightweight structure, allows it to run locally on internal PCs or self-servers, providing unparalleled security by keeping sensitive data within an organization's control, away from external cloud environments.
Industry observers view the "Privacy Filter" as a significant strategic move, expanding the generative AI competition beyond raw performance metrics into the essential domain of privacy protection infrastructure.
This model is not presented as a complete anonymization tool but as a foundational element, requiring human review in highly sensitive applications.
However, its potential applications are vast, from refining AI training data and enhancing search indexing to securing log storage and review systems, offering a robust platform for developers to build privacy-conscious applications from inception.

1. OpenAI's Privacy Filter: Technical Architecture and Release Details
To fully grasp the significance of OpenAI's announcement of its new Privacy Filter, it is essential to move beyond the headlines and delve into the technical underpinnings and release strategy that define this tool.
This section provides that crucial foundation, detailing the specific architecture, performance benchmarks, and distribution model that collectively enable the "Privacy Filter" to function as a powerful, accessible, and highly effective solution for protecting personal information.
These specifications are not merely abstract details; they are the core components that dictate the tool's real-world capabilities and its potential impact on developers and enterprises alike.
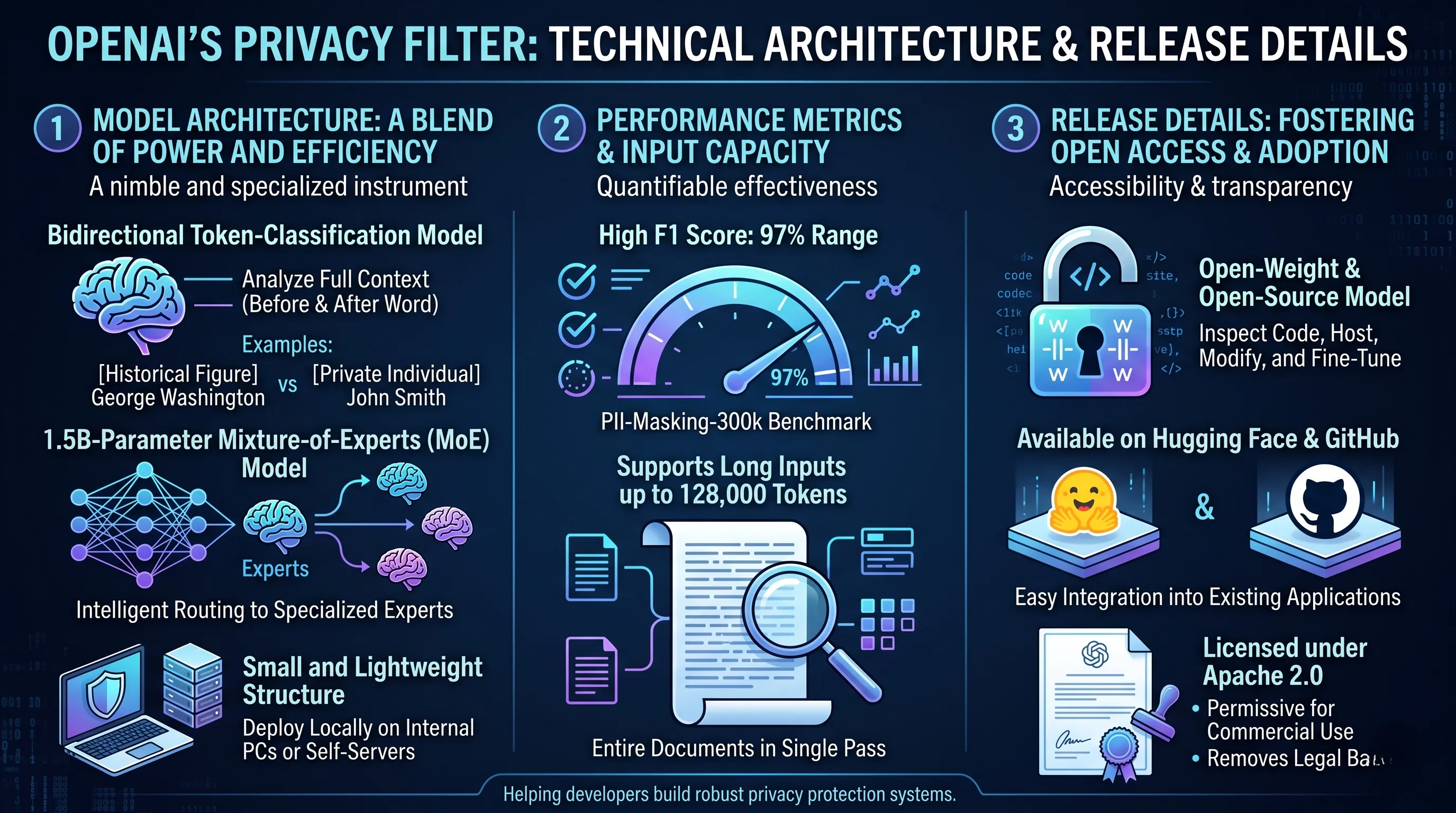
Model Architecture: A Blend of Power and Efficiency
The heart of the Privacy Filter is a sophisticated and meticulously designed model that balances raw processing power with a lightweight, efficient structure.
OpenAI has engineered this tool not as a monolithic, resource-intensive giant, but as a nimble and specialized instrument.
The core architecture is defined by several key characteristics:
Bidirectional token-classification model:
Unlike simpler tools that use regular expressions or one-way scanning to find patterns, the Privacy Filter employs a bidirectional approach.
This means it analyzes the full context of a word or "token" by looking at the text that comes both before and after it.
This contextual understanding is what allows it to make sophisticated judgments, such as correctly identifying "John Smith" as a private individual's name that needs masking in a customer support log, while recognizing "George Washington" in a historical document as a public figure's name that should be retained.
1.5B-parameter mixture-of-experts (MoE) model:
At 1.5 billion parameters, the model is undeniably powerful.
However, its true innovation lies in the mixture-of-experts architecture.
Instead of activating all 1.5 billion parameters for every single task, the MoE design intelligently routes each piece of input to a small, specialized subset of "experts" within the model.
This is the technical magic that allows it to achieve high performance without the massive computational overhead typically associated with models of this size, making it far more efficient to run.
Small and lightweight structure:
The MoE architecture directly enables its small and lightweight nature.
This efficiency is a game-changing feature, as it means the Privacy Filter can be deployed locally on internal company PCs or self-hosted servers.
This eliminates the need to send sensitive, unredacted data to an external cloud API, providing a fortress-like layer of security that is critical for industries handling confidential information.
Performance Metrics and Input Capacity
A model's architecture is only as good as its proven performance.
OpenAI has provided specific, impressive metrics that quantify the Privacy Filter's effectiveness and its capacity to handle demanding, real-world workloads.
Achieved F1 score in the 97% range on PII-Masking-300k benchmark:
This is a powerful, quantifiable statement of accuracy.
The F1 score, which harmonizes precision (minimizing false positives) and recall (minimizing false negatives), indicates an exceptionally high degree of reliability.
A score in the 97th percentile on a large-scale benchmark like "PII-Masking-300k" demonstrates the model's ability to consistently and accurately identify and mask Personally Identifiable Information (PII) across a vast and diverse set of examples.
For developers, this translates to a high level of trust that the tool will perform its critical function with minimal errors.
Supports long inputs up to 128,000 tokens:
This specification is an overwhelming weapon for enterprise applications.
Many AI models are constrained by small "context windows," forcing users to break large documents into smaller, disconnected chunks, which can lead to missed contextual cues.
The Privacy Filter's ability to process up to 128,000 tokens in a single pass is a massive advantage.
It allows for the seamless analysis of entire legal contracts, extensive customer inquiry records, years of chat logs, or complex technical documentation without fragmentation, ensuring that PII detection remains accurate even when context is spread across many pages.
Release Details: Fostering Open Access and Adoption
OpenAI's strategy for releasing the Privacy Filter is just as significant as the technology itself, emphasizing accessibility, transparency, and community integration.
The specifics of the release, published with research on April 22, 2026, are designed to maximize its adoption and utility.
Open-weight and open-source model:
This is a dual commitment to transparency.
"Open-source" means the underlying code is publicly available, while "open-weight" means the trained model parameters themselves are also released.
This allows any organization to not only inspect the code but also to host, modify, and fine-tune the model on their own proprietary data, potentially boosting its accuracy even further for specific industry jargon or document formats.
Available on Hugging Face and GitHub:
By placing the model on these central hubs of the AI and developer communities, OpenAI is ensuring it is trivially easy for developers to find, download, and integrate.
This strategy foregoes a proprietary API in favor of community-driven adoption, encouraging experimentation, feedback, and rapid integration into a wide array of existing and new applications.
Licensed under Apache 2.0:
The choice of the Apache 2.0 license is a critical business and community enabler.
This permissive license allows for free use, modification, and distribution of the software, even for commercial purposes, with very few strings attached.
It removes legal barriers for companies of all sizes to incorporate the Privacy Filter into their commercial products and internal workflows, directly supporting OpenAI's stated goal of helping developers build robust privacy protection systems from the earliest stages of development.
2. Advanced PII Detection: Core Capabilities and Intelligent Design
The significance of OpenAI's announcement of the 'Privacy Filter' is not merely the release of another tool, but the unveiling of a sophisticated, intelligently designed engine for data protection.
To truly grasp the impact of this release, we must delve into the core capabilities that define the filter's advanced approach to identifying and masking Personally Identifiable Information (PII).
These features collectively represent a major step forward, empowering developers to build privacy-centric systems with unprecedented ease and accuracy, directly fulfilling the main topic's promise of a powerful, accessible privacy solution.
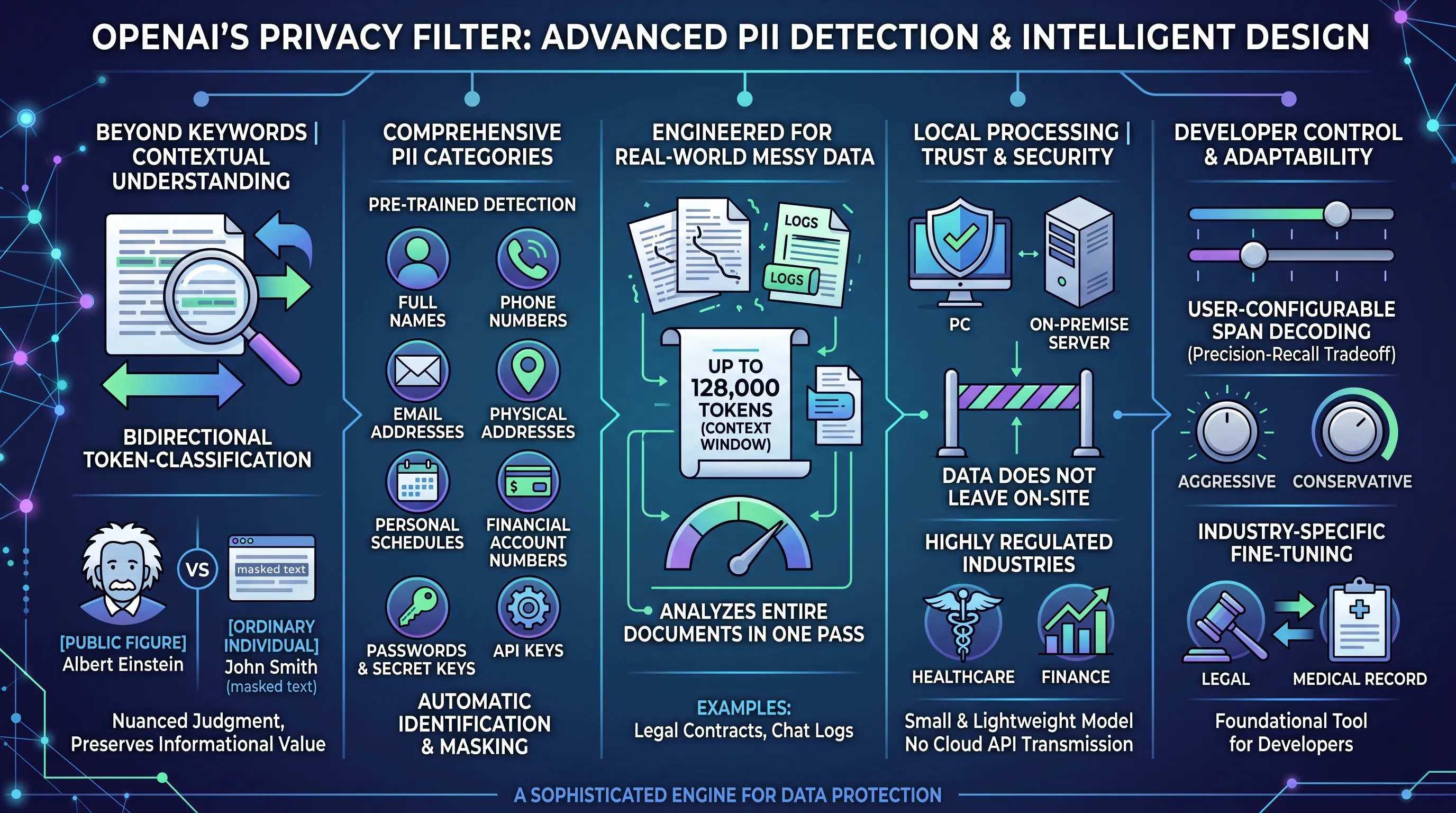
Beyond Keywords: The Power of Contextual Understanding
The Privacy Filter's most critical design feature is its departure from simplistic pattern matching, such as regular expressions (regex).
Instead, it operates as a bidirectional token-classification model, a sophisticated architecture that allows it to understand the meaning and context surrounding words, not just their literal form.
This is the key to its intelligent judgment.
For example, a basic pattern search might redact every name it finds, but the Privacy Filter is capable of a far more nuanced task: it can distinguish between the name of an ordinary individual in a customer support chat and the name of a public figure mentioned in a news article.
This sophisticated judgment is crucial for practical applications, ensuring that data can be sanitized for privacy without destroying its informational value, a common problem with older, less intelligent redaction methods.
Comprehensive and Specific PII Categorization
The model comes pre-trained to automatically identify and mask a wide and critical range of PII categories that developers constantly struggle with.
This isn't limited to the obvious targets like names and email addresses.
The filter is explicitly designed to find and neutralize:
- Full Names
- Phone Numbers
- Email Addresses
- Physical Addresses
- Personal Schedules and Appointments
- Financial Account Numbers
- Passwords and Secret Keys
- API Keys
This comprehensive coverage means developers have a single, powerful tool to handle the most common vectors for data leaks in documents, chat logs, and other text-based data sources.
Engineered for Real-World, Messy Data
A significant challenge in data privacy is that sensitive information rarely appears in perfectly formatted tables.
The Privacy Filter is specifically engineered to demonstrate high accuracy in unstructured text and long documents.
Its ability to process inputs up to 128,000 tokens is a testament to this design.
This capacity is far more than a vanity metric; it is a practical weapon for developers dealing with real-world artifacts like lengthy legal contracts, extensive customer inquiry records, or massive server log files.
The model can analyze these entire documents in one pass, preserving the full context necessary to accurately identify PII that might be missed if the text were broken into smaller, disconnected chunks.
Local Processing: The Cornerstone of Trust and Security
In a world of cloud-based APIs, the Privacy Filter’s ability to run locally on internal PCs or self-servers is a game-changing feature for security.
Because it is a small and lightweight model, developers do not need to transmit their most sensitive, raw data to an external server for processing.
This design choice eliminates an entire category of risk associated with data-in-transit and third-party data handling.
It allows organizations in highly regulated industries like finance and healthcare to integrate state-of-the-art PII detection directly into their secure, on-premise environments, ensuring that confidential information never leaves their control.
Fine-Grained Control for the Expert Developer
OpenAI recognizes that privacy is not a one-size-fits-all problem.
The Privacy Filter ships with user-configurable span decoding, a powerful feature that allows developers to control the model's precision-recall tradeoff.
In simple terms, they can "tune the dial" to make the model either more aggressive (ensuring no PII is ever missed, even at the risk of flagging some non-PII) or more conservative (ensuring it only flags text with very high confidence, at the risk of missing some ambiguous PII).
Furthermore, its potential for industry-specific accuracy improvements with minimal additional training is a massive advantage.
A legal firm could fine-tune it to better recognize case file numbers, or a hospital could adapt it for specific medical record formats, achieving significantly higher accuracy without the need for a massive, from-scratch model training effort.
This combination of control and adaptability is central to its mission: to serve as a foundational tool that helps developers easily build robust and tailored privacy protection systems right from the earliest stages of their projects.
3. Strategic Impact: Benefits, Limitations, and Industry Evolution
This section directly analyzes the strategic implications of OpenAI's release of its new 'Privacy Filter', exploring how its capabilities and deliberate limitations are set to reshape industry practices and the competitive AI landscape.
The filter’s introduction is not merely a technical update; it represents a calculated move into the foundational layer of AI safety and data governance, addressing one of the most significant barriers to enterprise AI adoption.
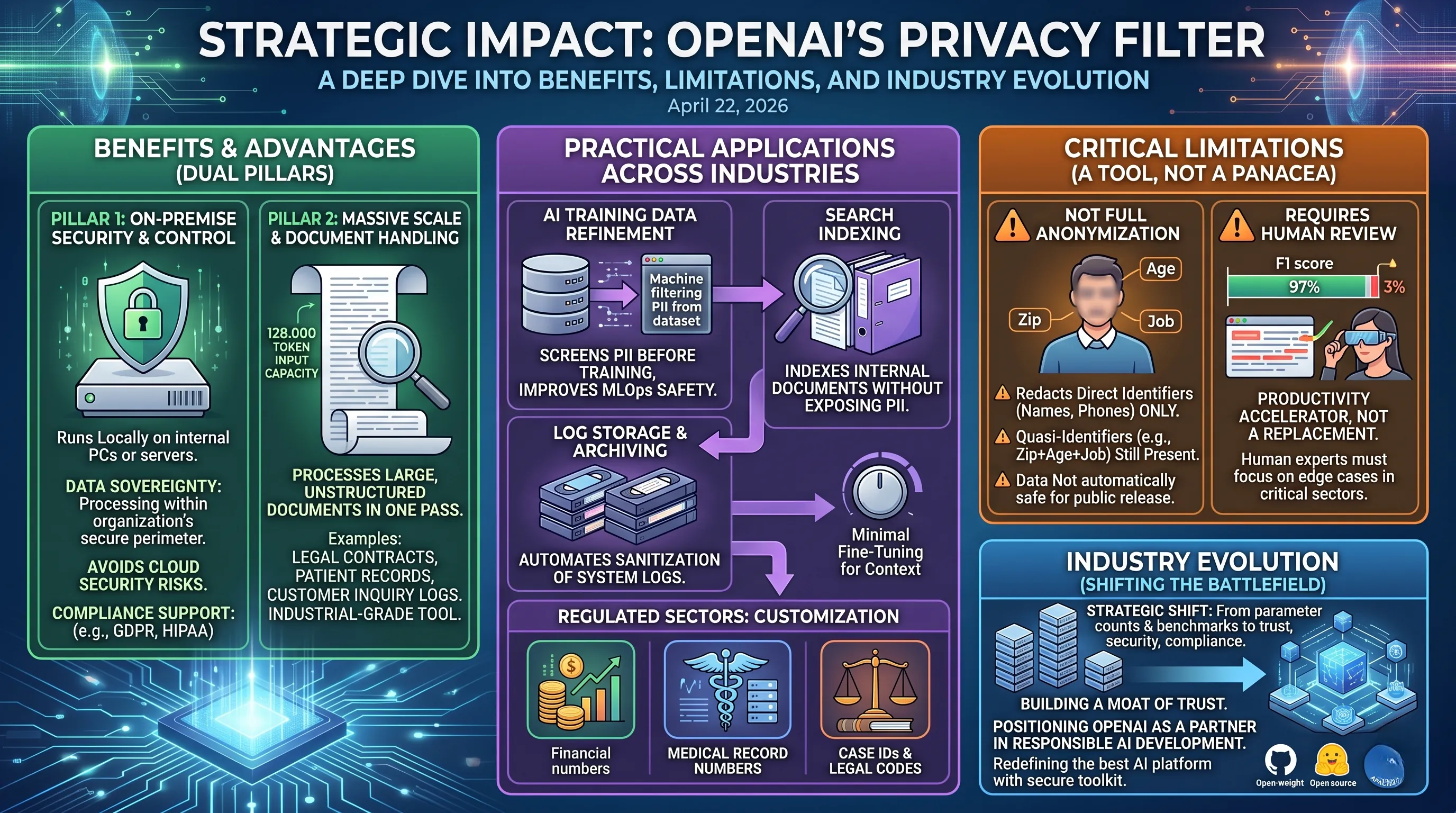
The Dual Pillars of Advantage: On-Premise Security and Massive Scale
The most profound benefit offered by the Privacy Filter stems from its architectural design, specifically its ability to run locally.
The model is engineered as a small and lightweight structure, a 1.5B-parameter mixture-of-experts model that can be deployed on internal PCs or self-hosted servers.
For organizations in sectors like finance, healthcare, or government, this is a game-changing feature.
It entirely sidesteps the primary security concern associated with cloud-based AI: the need to transmit sensitive, raw data to an external server.
By processing data entirely within an organization's own secure perimeter, the Privacy Filter offers a level of data sovereignty and control that API-based solutions simply cannot match.
This internal processing capability directly translates to enhanced security and compliance with stringent data protection regulations like GDPR and HIPAA.
Complementing this security-first approach is the filter's capacity for scale.
With support for inputs up to 128,000 tokens, the tool is not limited to sanitizing short chat messages or text snippets.
This immense input capacity makes it exceptionally suitable for handling large, unstructured documents.
Experientially, this means a legal firm can process an entire contract, a hospital can screen extensive patient records, or a tech company can sanitize vast customer inquiry logs in a single pass.
This ability to manage bulk data efficiently positions the Privacy Filter as an industrial-grade tool rather than a consumer-facing gadget, targeting the complex, high-volume data challenges faced by large enterprises.
Broadening the Horizon: Practical Applications Across Industries
The practical applications stemming from these core advantages are extensive and transformative.
One of the most immediate and impactful use cases is in AI training data refinement.
Developers constantly struggle with curating large datasets without inadvertently including PII, a mistake that can poison models and create massive legal liabilities.
The Privacy Filter provides a robust, automated first-pass solution to scrub this data *before* it is used for training, dramatically improving the safety and compliance of the entire MLOps pipeline.
Beyond training data, the filter is expected to be a crucial component in search indexing and log storage systems.
Companies can now index their internal documents—from HR records to customer support tickets—for powerful semantic search without exposing sensitive PII in the search results or the index itself.
Similarly, it can automatically sanitize system logs, which often contain user IPs, account details, or API keys, before they are archived, enhancing security and reducing the attack surface for data breaches.
The filter's potential is particularly pronounced in highly regulated sectors.
In finance, medical, and legal industries, the stakes are incredibly high.
The Privacy Filter’s design acknowledges this with its customizability; its accuracy can be significantly increased for domain-specific PII (e.g., medical record numbers, legal case IDs) with minimal additional fine-tuning.
This allows organizations to create a highly specialized, first-line-of-defense tool that understands their unique data context, a critical requirement where precision is non-negotiable.
A Tool, Not a Panacea: Understanding the Critical Limitations
Despite its power, OpenAI has been commendably transparent about the Privacy Filter's limitations.
Crucially, it is not presented as a complete anonymization tool.
It excels at detecting and masking direct identifiers like names and phone numbers, but it does not address quasi-identifiers (e.g., a combination of zip code, age, and profession) that could be used to re-identify individuals.
This is a critical distinction: the tool redacts PII but does not, by itself, create a fully anonymized dataset safe for public release.
Furthermore, OpenAI explicitly states that the tool requires human review in sensitive industries.
While its performance is high, achieving an F1 score in the 97% range on benchmarks, the remaining margin for error is unacceptable when dealing with legal contracts, patient diagnoses, or financial statements.
In these critical contexts, the Privacy Filter should be viewed as a powerful productivity accelerator for human reviewers, not a replacement.
It can handle the first 97% of the work, allowing human experts to focus their attention on the most complex edge cases and final verification, ensuring 100% accuracy where it matters most.
Shifting the Battlefield: From Performance Metrics to Privacy Infrastructure
The release of the Privacy Filter as an open-weight, open-source model under the permissive Apache 2.0 license is a clear strategic signal.
The industry evaluates this move as a deliberate expansion of the generative AI competition beyond raw model performance into the realm of privacy protection infrastructure.
For years, the race was defined by parameter counts, benchmark scores, and creative capabilities.
OpenAI is now changing the terms of engagement, recognizing that for enterprises, trust, security, and compliance are as important—if not more so—than the raw power of a large language model.
By giving away a foundational privacy tool, OpenAI is building a moat of trust and fostering an ecosystem around its technology.
It encourages developers to build robust privacy systems from the very early stages of their projects, positioning OpenAI not just as a model provider, but as a partner in responsible AI development.
This strategic pivot reframes the competition: the best AI platform is no longer just the one with the smartest model, but the one that provides the most comprehensive and secure toolkit for deploying that model in the real world.
📚 Related Posts
Google Deep Research Max: Gemini 3.1 Pro AI Agent Redefines Autonomous Enterprise Investigations & Report Generation for Regulat
🚀 Key TakeawaysGoogle's Deep Research Max is an autonomous AI agent, built on Gemini 3.1 Pro, designed to self-perform complex investigation and analysis tasks, effectively automating the entire research workflow from data exploration to report writing.
tech.dragon-story.com
OpenAI ChatGPT Images 2.0 Unveiled: First Inferential AI Model Transforms Visuals, Text & Multilingual Design for Production on
🚀 Key TakeawaysOpenAI's ChatGPT Images 2.0 (GPT-Image-2), officially released on April 21, 2026, represents a transformative leap as the first inferential image model.It excels in executing complex visual tasks, generating highly practical outputs such
tech.dragon-story.com
OpenAI GPT-5.5 Unveiled: Autonomous AI Redefines Coding, Research & Enterprise Productivity with Advanced Security & New API Pri
🚀 Key TakeawaysOpenAI's GPT-5.5 redefines AI by autonomously planning and executing complex multi-step tasks across coding, office work, and scientific research, boasting unprecedented intelligence, intuition, and advanced security measures.OpenAI has o
tech.dragon-story.com



