🚀 Key Takeaways
- Google's Gemini 3.1 Flash TTS ushers in a new era of voice AI, generating exceptionally natural, expressive, and human-like voices with unprecedented control through 'Audio Tags' and intuitive prompts, making advanced voice synthesis broadly accessible and globally scalable across over 70 languages.
Google has unveiled Gemini 3.1 Flash TTS, a groundbreaking next-generation voice AI model poised to revolutionize how we interact with synthetic audio.
This preview model from the Gemini 3 family is already achieving impressive scores in evaluations, demonstrating a remarkable ability to generate voices that closely rival human speech in terms of naturalness, precision, and expressiveness, while also balancing quality and cost-efficiency.
A core innovation of Gemini 3.1 Flash TTS is its sophisticated control system, featuring 'Audio Tags' and natural language prompts.
Users can now direct the AI voice with granular precision, much like a film director, to influence vocal style, speed, and emotional nuances such as [whispers], [laughs], or even dramatic pauses.
This capability extends to generating complex, emotive narratives and multi-speaker conversations across over 70 languages, significantly accelerating global content production and fostering truly dynamic voice interactions for various applications including customer service, content creation, and education.
Beyond its advanced performance and expressiveness, Google has made Gemini 3.1 Flash TTS freely accessible on Google AI Studio without requiring an API key, democratizing access to cutting-edge voice synthesis.
Concurrently, addressing growing concerns regarding AI-generated fake voices, Google has integrated an invisible watermark called 'SynthID' into all generated audio, ensuring transparency and responsible use as AI voice technology advances to this unprecedented 'acting stage'.

1. Google Gemini 3.1 Flash TTS: A New Benchmark in Voice AI
This section directly addresses the core of our main topic, "Google's 'Gemini 3.1 Voice' Aims for Human-Like Voice," by dissecting the engine driving this ambition.
Gemini 3.1 Flash TTS is not merely an incremental update; it is the foundational technology and the next-generation voice AI model from Google that embodies this quest for human-level vocal replication.
Every feature, from its performance metrics to its fine-grained emotional control, is a deliberate step towards closing the gap between artificial speech and authentic human expression.
A New Standard in Performance and Efficiency
Google has introduced Gemini 3.1 Flash TTS as a Preview model, signaling its cutting-edge nature while inviting the developer community to explore its capabilities.
This isn't just another text-to-speech system; it's a model engineered to set a new benchmark, and early results validate this claim.
On the highly respected Artificial Analysis TTS leaderboard, which relies on blind human preference tests, Gemini 3.1 Flash TTS has already achieved impressive scores.
This is a critical distinction: the model excels not just on machine-based metrics but in the ultimate test—whether a human listener perceives its output as superior, more natural, and more pleasant.
This high performance is achieved while masterfully balancing quality and cost-efficiency, a crucial combination for widespread adoption.
Furthermore, Google has focused on core user experience metrics, delivering improved precision and lower latency for voice interactions.
Experientially, this translates into conversations that feel fluid and responsive, eliminating the awkward, tell-tale pauses that have historically plagued AI voice agents and made them feel distinctly robotic.
It's the difference between a stilted dialogue and a natural, flowing exchange, bringing the model one step closer to mirroring human conversation patterns.
Democratizing Advanced Voice Generation
In a significant move to accelerate innovation, Google has made this powerful tool remarkably accessible.
Gemini 3.1 Flash TTS is available free on Google AI Studio, a decision that removes the primary barrier to entry for developers, creators, and researchers.
Critically, users do not need an API key to get started, allowing for immediate experimentation with the full access to its extensive voice library and the inline tag system.
As an integral part of the Gemini 3 family of models, it benefits from the broader ecosystem and architectural advancements of Google's latest AI generation, ensuring it is both powerful and well-integrated.
This open-access strategy is poised to unleash a wave of creativity, enabling everyone from indie game developers to global content producers to leverage world-class voice AI without prohibitive costs.
The Director's Chair: Granular Control Over Vocal Performance
The true leap forward with Gemini 3.1 Flash TTS lies in its ability to generate much more natural and expressive voices than its predecessors.
The centerpiece of this capability is the 'Audio Tags' function, a revolutionary feature that provides users with fine-grained control over vocal style, speed, and emotional expression.
This transforms the user from a simple prompter into a director.
Instead of accepting a default AI tone, creators can now embed simple instructions directly within the text to command nuanced performances.
For example, a user can instruct the AI to change its delivery using simple tags like [whispers] or [laughs], or by using natural language prompts such as "in an excited tone," "with a sarcastic delivery," or adding a [dramatic pause] for effect.
This makes it possible to create entire emotive narratives and complex conversations.
The model is capable of handling dialogues with multiple speakers and complex emotional changes, allowing for the generation of audio that sounds like a genuine interaction rather than a series of disconnected statements.
With support for over 70 languages, this feature dramatically accelerates the potential for global content production, enabling creators to easily produce high-quality, emotionally resonant voice content for diverse cultures and countries.
Applications, Issues, and Responsible Innovation
The potential applications for such an advanced tool are vast, spanning customer service bots that can sound truly empathetic, educational content that captivates students with dynamic narration, and a new era of automated content creation for podcasts and audiobooks.
However, the very power that makes this technology so promising also raises a growing concern over the potential for creating convincing fake voices for malicious purposes.
Google is proactively addressing this critical issue.
To distinguish its AI-generated audio, Google is embedding an invisible digital watermark called 'SynthID' into all voices produced by the model.
This watermark is designed to be robust and difficult to remove, providing a reliable method for identifying the AI origin of a voice clip.
As experts note, AI is rapidly progressing into an "acting stage," where it can convincingly perform roles and emotions.
This leap in capability underscores the immense importance of responsible development and use, with safeguards like SynthID serving as a crucial first line of defense in ensuring the technology is used ethically.

2. Unleashing Human-Like Expression: Gemini 3.1's Advanced Vocal Control
This section directly addresses the core thesis that Google's Gemini 3.1 is aiming to surpass the human voice, as it moves beyond simple speech replication into the realm of nuanced emotional performance and directorial control.
The leap from previous models to Gemini 3.1 is not merely an incremental improvement in clarity; it is a fundamental shift in how users can interact with and shape synthetic audio.
It is this unprecedented level of fine-grained control over vocal expression that truly allows the AI to challenge the expressiveness once exclusive to human actors.
From Transcriber to Director: The Power of Audio Tags and Prompts
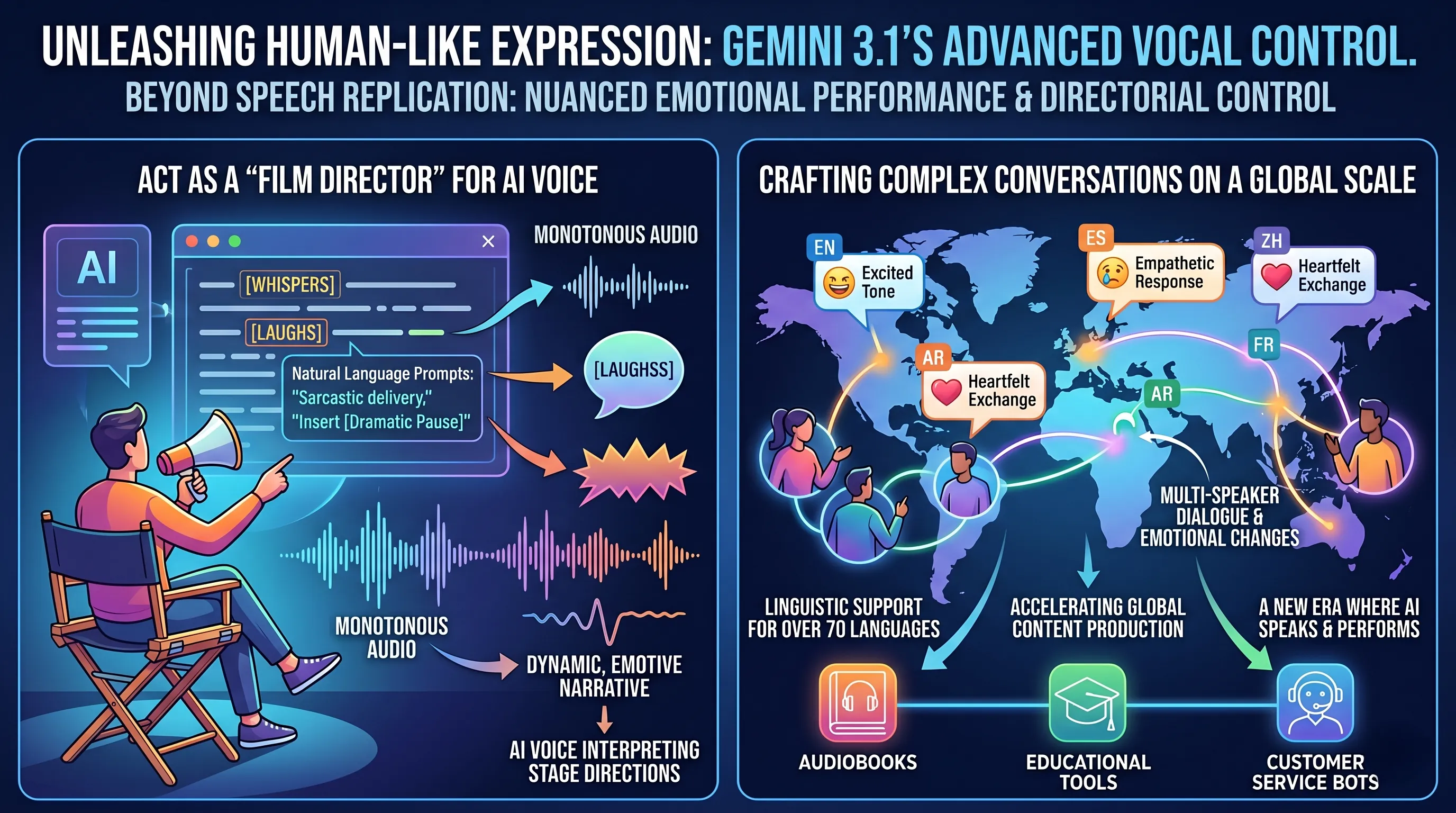
The most groundbreaking feature of the Gemini 3.1 Flash TTS model is its ability to empower the user to act as a "film director" for the AI voice.
This is achieved through a powerful combination of 'Audio Tags' and natural language prompts, which serve as stage directions embedded directly within the text.
Instead of simply converting words into a monotonous audio track, the model interprets these cues to modulate its performance, infusing the speech with specific styles, speeds, and emotional states.
This system provides an intuitive yet profound level of control.
Users can employ simple, bracketed Audio Tags like [whispers] to create a sense of intimacy or secrecy, or [laughs] to inject genuine-sounding mirth into a sentence.
Furthermore, the model understands more abstract natural language prompts, allowing for directions such as "speaking in an excited tone," adopting a sarcastic delivery, or inserting a perfectly timed [dramatic pause] to build tension.
This capability transforms a static script into a dynamic, emotive narrative, giving creators the tools to craft complex audio experiences that were previously impossible without hiring and directing human voice talent.
Crafting Complex Conversations on a Global Scale
Gemini 3.1's expressive power is not limited to a single monologue.
The technology is fully capable of generating natural conversations with multiple speakers, managing the intricate back-and-forth and complex emotional changes that define human dialogue.
This allows for the creation of entire scenes, from a heated debate to a heartfelt exchange, all generated from a single text prompt.
This feature alone has massive potential for applications in content creation, such as producing audiobooks with distinct character voices or scripting dynamic educational content.
Compounding this capability is the model's extensive linguistic support, covering over 70 languages.
This is a critical factor in "accelerating global content production."
It means that creators can easily generate high-quality, emotionally resonant voice content for diverse countries and cultures without the logistical and financial burden of sourcing and managing a multinational cast of voice actors.
The ability to maintain expressive control across this vast linguistic spectrum democratizes the creation of sophisticated audio for a worldwide audience.
As a result, from customer service bots that can convey empathy to educational tools that can engage students with compelling storytelling, the potential for this technology is immense, marking a new era where AI is not just speaking, but truly performing.
3. Innovating Responsibly: Gemini 3.1's Impact and Google's Commitment to Authenticity
As Google's Gemini 3.1 voice AI inches ever closer to indistinguishably human expression, fulfilling the article's central theme of "aspiring to the human voice," the conversation must pivot from mere technological marvel to its real-world impact and the ethical guardrails required.
The very success of this technology in mimicking humanity necessitates a profound commitment to responsible innovation, a balance between unlocking potential and preventing misuse.
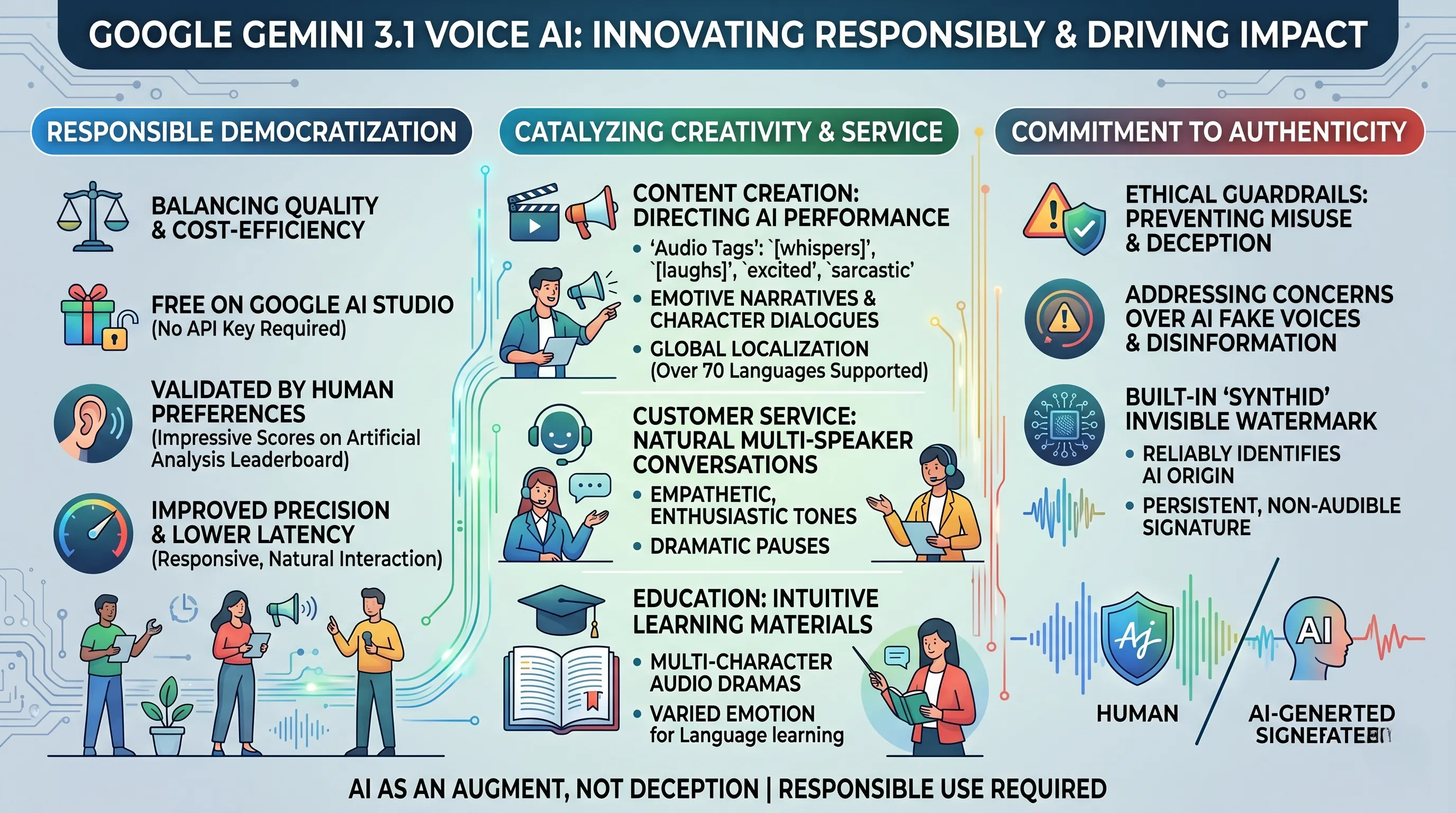
The Democratization of Professional-Grade Audio
Historically, high-quality voice generation has been a trade-off between quality and cost.
Gemini 3.1 Flash TTS shatters this paradigm by explicitly balancing quality and cost-efficiency.
This is not a minor adjustment; it represents a fundamental shift in accessibility.
By achieving impressive scores on the Artificial Analysis TTS leaderboard, which relies on blind human preferences, Google validates the model's quality against the ultimate metric: the human ear.
Simultaneously, by making it free on Google AI Studio with no API key required, Google removes the financial and technical barriers that once reserved such powerful tools for large corporations.
This combination means a solo indie game developer, a teacher creating e-learning modules, or a small business owner crafting a promotional video now has access to a voice library and control system that was previously the domain of high-budget studios.
The model’s improved precision and lower latency further amplify its practical value, ensuring that interactive applications feel responsive and natural, not sluggish and robotic.
A Catalyst for Creativity and Service Across Sectors
The true impact of Gemini 3.1 is revealed in its diverse applications, moving far beyond simple text-to-speech to become a tool for performance and connection.
For Content Creation: This technology is a director's dream.
The inclusion of 'Audio Tags' and the ability to use simple natural language prompts like "[whispers]", "[laughs]", "excited", or "sarcastic" transforms a user from a typist into a vocal choreographer.
One can now direct the AI to deliver lines with specific emotional weight, creating emotive narratives and entire conversations with nuanced character interactions.
The support for over 70 languages is a massive accelerator for global content production, allowing a creator to localize their work for various cultures not just with translation, but with appropriate vocal expression, all from a single interface.
For Customer Service: The model's ability to engage in natural conversations with multiple speakers and complex emotional changes signals the potential end of frustrating, monotone automated systems.
An AI-powered service agent can now sound genuinely empathetic, adopt an enthusiastic tone, or insert a "dramatic pause" for emphasis, drastically improving the customer experience and allowing human agents to focus on more complex issues.
For Education: The potential to create engaging learning materials is immense.
History lessons can be transformed into multi-character audio dramas, and language-learning apps can provide examples of speech with a wide range of emotions and intonations, making the process more intuitive and memorable.
The Ethical Frontier: Watermarks and the "Acting Stage"
The very power that makes Gemini 3.1 so compelling—its ability to generate incredibly natural and expressive voices—also fuels a growing concern over fake voices created by AI technology.
As the line between human and AI-generated audio blurs, the risk of malicious use, from scams to disinformation, becomes critically important to address.
Google's primary technical response to this is proactive and built-in: the embedding of an invisible watermark called 'SynthID' in all generated voices.
This is a crucial commitment to authenticity.
SynthID acts as a non-audible, persistent signature that can be detected to reliably identify the AI origin of a piece of audio, providing a foundational layer of transparency without compromising the user's creative output.
However, experts rightly emphasize that technology alone is not enough.
As AI voice generation progresses to what is being called an 'acting stage'—where it is no longer just narrating but performing with emotion and intent—the importance of responsible use by the community becomes paramount.
Google's framework is a call to action for creators and developers to be transparent about their use of AI voices, ensuring that this powerful new capability is used to augment human creativity, not to deceive human perception.
📚 Related Posts
Google Gemini macOS App: Always-On AI Revolutionizes Desktop Workflow with Native Integration & Screen Understanding
🚀 Key TakeawaysGemini for macOS acts as an "always-on" AI assistant, deeply integrating into your workflow with a native macOS experience and providing instant, contextual assistance.Leveraging the powerful Gemini 3 model, it uniquely understands screen
tech.dragon-story.com
Claude Code: The AI Orchestration Platform Redefining Development with Parallel AI & Doubled Autonomy
🚀 Key TakeawaysClaude Code revolutionizes the development workflow by enabling parallel AI tasks, fundamentally shifting the developer's role to an AI orchestrator.The platform offers an integrated and highly customizable development environment with fe
tech.dragon-story.com
OpenAI Codex Unleashed: Autonomous AI Agents Take Direct Computer Control & Reshape Software Development with LLMs, Copilot & AI
🚀 Key TakeawaysOpenAI Codex has undergone a major transformation, evolving into a sophisticated AI agent capable of direct computer control, autonomous task execution, and managing entire development lifecycles, thus becoming a true collaborator rather
tech.dragon-story.com



